Подготовка и отладка программы
Процесс подготовки и отладки программы на языке ассемблера включает этапы подготовки исходного текста, трансляции, компоновки и отладки.
Подготовка исходного текста программы выполняется с помощью любого текстового редактора, хотя бы редактора, встроенного в программу Norton Commander, или еще более удобного редактора Norton Editor. При использовании одного из более совершенных текстовых процессоров, вроде Microsoft Word, следует иметь в виду, что эти программы добавляют в выходной файл служебную информацию о формате (размер страниц, тип шрифта и др.), которая будет непонятна транслятору. Однако практически все текстовые редакторы и процессоры позволяют вывести в выходной файл "чистый текст", без каких-либо служебных символов. Именно таким режимом и надлежит воспользоваться в нашем случае.
В принципе для подготовки исходного текста можно воспользоваться любым редактором системы Windows, например, программой WordPad или Блокнотом. Однако в этом случае возникнут неприятности с русским шрифтом. Как известно, корпорация Microsoft приняла для своих русифицированных продуктов собственную кодировку русских символов, расходящуюся со стандартной, используемой в приложениях DOS. Если программу, использующую русский текст в качестве комментариев, или выводящую его на экран, подготовить в одном из редакторов Windows, то при ее просмотре и запуске в среде DOS вместо русского текста вы увидите бессмысленный набор символов. Поэтому программы, предназначенные для выполнения под управлением MS-DOS, лучше и подготавливать в среде DOS. Файл с исходным текстом должен иметь расширение .ASM.
Следующая операция состоит в трансляции исходного текста программы, т.е. в преобразовании строк исходного языка в коды машинных команд. Эта операция выполняется с помощью транслятора с языка ассемблера (т.е. с помощью программы ассемблера). Известные разработчики программного обеспечения - корпорации IBM, Borland, Microsoft и др. предлагают свои варианты трансляторов, несколько различающиеся своими возможностями и системой обозначений. Однако входной язык любого транслятора, включающий в себя мнемонику машинных команд и других операторов и правила написания предложений ассемблера, для всех ассемблеров одинаков, поэтому при подготовке и отладке примеров данной книги можно с равным успехом воспользоваться любой из указанных программ. Мы, как уже отмечалось, использовали программы пакета TASM 5.0 (фирменные названия этих программ - Turbo Assembler,
Turbo Link и Turbo Debugger, а имена соответствующих им файлов - TASM.EXE, TLINK.EXE и TD.EXE).
После трансляции образуются два файла - листинг трансляции и объектный файл с расширением OBJ. Листинг представляет собой текстовый файл, предназначенный для чтения в каком-либо редакторе, и содержит исходный текст оттранслированной программы вместе с машинными кодами команд. В случае обнаружения транслятором каких-либо ошибок, в листинг также включаются сообщения об этих ошибках.
Рассмотрим элементы листинга трансляции примера 1-1 из предыдущей главы. На рис. 2.1 приведен несколько сокращенный текст этого листинга, из которого удалены комментарии к отдельным предложениям.
айту. В этом случае следует использовать перетаскивание в обратном направлении. А именно, разыщите целевой файл, например, при помощи программы Проводник, затем перетащите его значок на карту узла — на изображение родительского документа.

Рис. 2.1. Листинг трансляции программы 1-1.
Рассматривая листинг, можно отметить ряд полезных моментов общего характера. Предложения программы с операторами assume, segment, ends, end, как уже отмечалось ранее, не транслируются в какие-либо машинные коды и не находят отражения в памяти. Они нужны лишь для передачи транслятору служебной информации о способе трансляции команд (assume), границах сегментов (segment и end) и строке, на которой следует завершить обработку исходного текста (end).
Каждому транслируемому предложению программы соответствует определенное смещение, причем задание смещений выполняется в каждом сегменте в отдельности. Первая команда mov AX,data имеет смещение от начала сегмента команд, равное нулю. Она занимает 3 байта, поэтому следующая команда начинается с байта 3 и имеет соответствующее смещение.
Транслятор не смог полностью определить код команды mov AX,data. В этой команде в регистр АХ засылается сегментный адрес сегмента data. Однако этот адрес станет известен лишь в процессе загрузки выполнимого файла программы в память. Поэтому в листинге на месте этого адреса стоят нули, помеченные буквой s, напоминающей о том, что здесь должен быть пока неизвестный сегментный адрес.
Еще одна помеченная команда с кодом ВА 0000 располагается в строке 8 листинга. В этой команде в регистр DX заносится смещение поля с именем msg, расположенное в сегменте данных (ключевое слово offset, указанное перед именем поля, говорит о том, что речь идет не о содержимом ячейки msg, а об ее смещении). Поле msg расположено в самом начале сегмента данных, и его смещение от начала сегмента равно 0, что и указано в коде команды. Почему же эта команда помечена буквой т, являющейся сокращением слова relocatable, переместимый?
Чтобы ответить на этот вопрос, нам придется рассмотреть, как сегменты программы размещаются в памяти. Как уже говорилось, любой сегмент может располагаться в памяти только с адреса, кратного 16, т.е. на границе 16-байтового блока памяти (параграфа). Конкретный адрес программы в памяти зависит от конфигурации компьютера, - какой размер занимает DOS, сколько загружено резидентных программ и драйверов, а также в каком режиме запускается программа - в отладчике или без него. Предположим, что сегментный адрес сегмента команд оказался равным 1306п (рис. 2.2, а). В нашей программе сегмент команд имеет размер 11h байт (что указано в строке 13 листинга), т.е. занимает целый параграф плюс один байт. Сегмент данных имеет размер 14h байт (строка 19 листинга) и тоже требует для своего размещения немного больше одного парафафа. Из-за того, что сегмент данных должен начаться на границе параграфа, ему будет назначен сегментный адрес 1308h и между сегментами образуется пустой промежуток размером 15 байт.
Потеря 15 байт из многомегабайтовой памяти, разумеется, не имеет никакого значения, однако в некоторых случаях, например, при компоновке единой профаммы из большого количества модулей с небольшими по размеру подпрофаммами, суммарная потеря памяти может оказаться значительной.
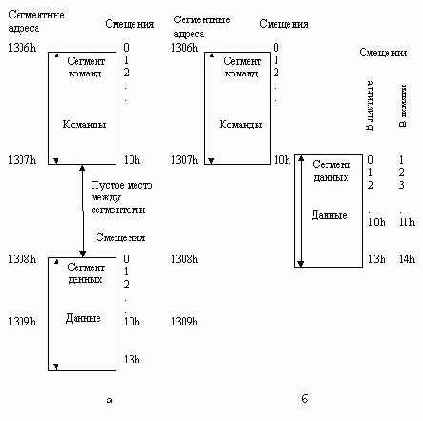
Рис. 2.2. Расположение сегментов программы в памяти при выравнивании по умолчанию (а) и на байт (б).
Для того, чтобы устранить потери памяти, можно сегмент данных объявить с выравниванием на байт:
data segment byte
Такое объявление даст возможность системе загрузить сегмент данных так, как показано на рис. 2.2, б. Сегмент данных частично перекрывает сегмент команд, начинаясь на границе его последнего параграфа (в нашем случае по адресу 1307h). Для того, чтобы данные не наложились на последние команды сегмента команд, они смещаются вниз так, что начинаются сразу же за сегментом команд. В нашем примере, где сегмент команд "выступает" за сегментный адрес 1307h всего на 1 байт, данные и надо сместить на этот 1 байт. В результате поле msg, с которого начинается сегмент данных, и которое в листинге имело смещение 0, получит смещение 1. Все остальные адреса в сегменте данных также сместятся на один байт вперед. В результате данные будут располагаться в физической памяти вплотную за командами, без всяких промежутков, однако все обращения в сегменте команд к данным должны быть скорректированы на величину перекрытия сегментов, в нашем случае - на 1 байт. Эта коррекция выполняется системой после загрузки программы в память, но еще до ее запуска. Адреса, которые могут потребовать описанной коррекции, и помечаются в листинге трансляции буквой "г".Из сказанного следует очень важный и несколько неожиданный вывод: коды команд программы в памяти могут не совпадать с кодами, показанными в листинге трансляции. Это обстоятельство необходимо учитывать при отладке программ с помощью интерактивного отладчика, который, естественно, показывает в точности то, что находится в памяти, и что не всегда соответствует листингу трансляции.
Вернемся к рассмотрению листинга трансляции. Данные, введенные нами в программу, также оттранслировались: вместо символов текста в загрузочный файл попадут коды ASCII этих символов. Так, буква "П" преобразовалась в код 8Fh, буква "р" в код ЕО и т. д. При выводе этих кодов на экран видеосистема компьютера преобразует их назад в изображения символов, записанных в исходном тексте программы.
Из листинга трансляции легко определить размер отдельных составляющих программы. В нашем случае длина сегмента команд составляет 11h = 17 байт, длина сегмента данных - 14h = 20 байт, а под стек отведено ровно столько, сколько мы запросили в программе - 100h = 256 байт. Размер же всей программы окажется больше суммы длин сегментов, во-первых, из-за пустых промежутков между сегментами (у нас на них уйдет 15 + 12 = 27 байт), и, во-вторых, за счет подсоединения к программе обязательного префикса программы, имеющего всегда размер 256 байт.
Как мы уже отмечали, в результате трансляции программы образуется два файла - с листингом и с объектным модулем программы.
Объектный файл является основным результатом работы транслятора и представляет собой текст программы, преобразованный в машинные коды. Хотя в этом файле уже присутствуют коды команд, он не может быть выполнен. Для того чтобы получить выполнимую программу, объектный файл необходимо скомпоновать.
Компоновка объектного файла выполняется с помощью программы компоновщика (редактора связей). Эта программа получила такое название потому, что ее основное назначение - подсоединение к файлу с основной программой файлов с подпрограммами и настройка связей между ними. Однако компоновать необходимо даже простейшие программы, не содержащие подпрограмм. Дело в том, что у компоновщика имеется и вторая функция - изменение формата объектного файла и преобразование его в выполнимый файл, который может быть загружен в оперативную память и выполнен. Файл с программой компоновщика обычно имеет имя LINK.EXE, хотя это может быть и не так. Например, компоновщик пакета TASM назван TLINK.EXE. В результате компоновки образуется загрузочный, или выполнимый файл с расширением .ЕХЕ.
Отладку и изучение работы готовой программы удобнее всего осуществлять с помощью интерактивного отладчика, который позволяет выполнять отлаживаемую программу по шагам или с точками останова, выводить на экран содержимое регистров и областей памяти, модифицировать (в известных пределах) загруженную в память программу, принудительно изменять содержимое регистров и выполнять другие действия, позволяющие в наглядной и удобной форме контролировать выполнение программы.
Рассмотрим вкратце основные приемы работы с "турбоотладчиком" TD.EXE из пакета TASM. Приступая к работе с отладчиком, следует убедиться, что в рабочем каталоге имеются и загрузочный (Р.ЕХЕ), и исходный (P.ASM) файлы, так как отладчик в своей работе использует оба эти файла. Для запуска отладчика следует ввести команду
td р
На экране появится кадр отладчика, в котором видны два окна - окно Module с исходным текстом отлаживаемой программы и окно Watches для наблюдения за ходом изменения заданных переменных в процессе выполнения программы (рис. 2.3). Окно Watches нам не понадобится, и его можно убрать, щелкнув мышью по маленькому квадратику в левом верхнем углу окна, или введя команду <Alt>+<F3>, предварительно сделав это окно активным. Переключение (по кругу) между окнами осуществляется клавишей <F6>.
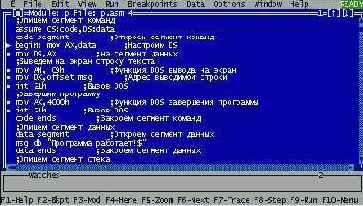
Рис. 2.З. Начальный кадр отладчика с текстом отлаживаемой программы.
В процессе отладки программы на экран приходится выводить много дополнительных окон; они перекрываются и часто скрывают друг друга. Чтобы увидеть их все одновременно, размер окон приходится уменьшать, а сами окна перемещать по экрану. Режим изменения размеров и положения окна включается командой <Ctrl>+<F5>, после чего клавиши со стрелками перемещают окно по экрану, а те же клавиши при нажатой клавише <Shift> позволяют изменять его размер. Выход из режима настройки окна осуществляется нажатием клавиши <Enter>.
Начальное окно отладчика дает слишком мало информации для отладки программы. В нем можно выполнять программу по частям до местоположения курсора (клавиша <F4>) и команда за командой (клавиша <F8>); можно также с помощью окна Watches наблюдать изменения заданных полей данных. Однако для отладки программы на уровне языка ассемблера необходимо контролировать все регистры процессора, включая регистр флагов, а также, во многих случаях, поля данных вне программы (например, векторы прерываний или системные таблицы). Гораздо более информативным является "окно процессора", которое вызывается с помощью пункта Vicw>CPU верхнего меню или командой <Alt>+<V>+<C> (рис. 2.4).

Рис. 2.4. Окно процессора с внутренними окнами.
Окно процессора состоит, в свою очередь, из 5 внутренних окон для наблюдения текста программы на языке ассемблера и в машинных кодах, регистров процессора, флагов, стека и содержимого памяти. С помощью этих окон можно полностью контролировать ход выполнения отлаживаемой программы. Для того чтобы можно было работать с конкретным окном, например, прокручивать его содержимое, надо сделать его активным, щелкнув по нему мышью. Перейти из окна в окно можно также с помощью клавиатуры, нажимая клавишу Tab. Посмотрим, какие сведения можно извлечь из содержимого окна процессора.
Содержимое сегментных регистров DS и ES одинаково и составляет HF5h. Эта значит, что программа загружена в память, начиная с физического адреса 11F50, т.е. приблизительно с 70-го килобайта. Чем заняты первые 70 Кбайт памяти? Обычно компьютер конфигурируется так, что в обычной памяти размещается только малая часть DOS (около 16 Кбайт), драйверы обслуживания расширенной памяти и резидентная часть COMMAND.COM. Основная часть DOS, остальные драйверы и необходимые резидентные программы (например, русификатор) переносятся в расширенную память. В этом случае системные области в начале памяти занимают всего 20 - 25 Кбайт. Тем не менее наша программа начинается не с 25-го, а с 70-го килобайта. Произошло это из-за того, что программа запущена под управлением отладчика, который сначала загружается в память сам, и лишь затем загружает отлаживаемую программу. Но отсюда следует, что если бы мы запустили программу без отладчика, она попала бы на другое место в памяти, гораздо ближе к ее началу. В большинстве случаев это обстоятельство не имеет особого значения, так как любая программа должна одинаково успешно выполняться в любом месте памяти, однако необходимо отдавать себе отчет, что отладчик изменяет операционную среду программы (в частности, переносит ее на другое место в памяти). Строго говоря, программа под управлением отладчика выполняется не совсем так, как она выполнялась бы непосредственно в DOS.
Еще один пример "самодеятельности" отладчика можно увидеть в том же окне регистров процессора. Содержимое всех регистров общего назначения (АХ, ВХ, СХ, DX, SI, DI и ВР) равно 0. Отсюда можно сделать вывод, что DOS, загружая программу в память, очищает регистры процессора. Однако на самом деле это совсем не так! Регистры очищает не DOS, а отладчик. При обычном запуске программы исходное содержимое регистров практически непредсказуемо, и ни в коем случае нельзя рассчитывать, что в них будут нули. Иногда можно столкнуться и с более тонким влиянием отладчика на ход выполнения программы, вплоть до того, что некоторые виды программ, например, управляющие подключенной к компьютеру аппаратурой, в отладчике будут выполняться просто неверно.
Итак, после загрузки программы в память содержимое регистров DS и ES оказалось одинаковым. Это вполне естественно, если вспомнить, что перед выполнением оба регистра указывают на префикс программы (см, рис. 1.9). Вслед за префиксом располагается сегмент команд и поскольку префикс всегда занимает точно lOOh байт (т.е. 10h параграфов по 16 байт), то содержимое CS в нашем случае должно быть равно HF5h + 10h = 1205h. Так оно и есть (см. рис. 2.4).
В нашем примере программа должна начать выполняться с метки begin, поскольку именно эту метку мы указали в качестве операнда завершающей директивы end. Эта метка относится к самой первой команде сегмента команд и ее значение (или, что то же самое, смещение первой команды программы) должно быть равно 0. Поэтому исходное значение указателя команд, как это видно из рис. 2.4, тоже равно 0. В дальнейшем, по мере выполнения команд, значение IP будет возрастать. Выполним две первые команды программы, дважды нажав клавишу <F8>. Состояние программы после этой операции показано на рис. 2.5.

Рис. 2.5. Состояние программы после выполнения двух первых команд.
Видно, что указатель команд получил значение 5 и показывает на очередную (еще не выполнявшуюся) команду mov AH,09h, относительный адрес которой равен 5. Сегментный регистр DS получил значение 1207h, что должно соответствовать сегментному адресу сегмента данных. Вспомним, что сегмент команд у нас занимает 11h байт и требует в памяти 2 параграфа. Сегмент команд имеет сегментный адрес 1205h, следовательно, сегментный адрес сегмента данных должен быть равен 1207h, что мы и получили.
Обратим внимание на самую правую колонку в окне процессора, в которой индицируются состояния флагов процессора. Как уже говорилось, состояния флагов заново устанавливаются процессором после выполнения каждой команды, и по ним можно в определенной степени судить о результате команды. С самого начала у нас был установлен только флаг IF (i в окне отладчика), что свидетельствует о включенном механизме аппаратных прерываний; остальные флаги сброшены. После выполнения двух первых команд состояние регистра флагов не изменилось. Произошло это потому, что команда пересылки mov не изменяет состояния флагов. Поскольку в нашей программе нет никаких команд, кроме mov и hit, а команда hit тоже состояния флагов обычно не изменяет, то наблюдать с помощью нашего примера функционирование регистра флагов не удастся.
Рассмотрим теперь стек. Сегмент данных имеет у нас размер 14h байт, и под него в памяти надлежит выделить 2 параграфа. Это объясняет содержимое сегментного регистра стека SS - 1209п. Под стек отведено 256 байт, поэтому исходное положение SP (под дном стека) соответствует смещению l00h.
Наконец, стоит еще обратить внимание на нижнюю половину окна команд, заполненную странными командами add [bx+si],al. Таких команд, да еще в таком количестве, в нашей программе нет, их "придумал" отладчик, пытаясь деассемблировать промежуток между сегментом команд и сегментом данных, заполненный нулями. Код 0000h соответствует команде add [bx+si],al, которую и изобразил отладчик.
Таким образом, рассмотрев информацию, предоставленную отладчиком, мы подтвердили все предыдущие рассуждения о расположении в памяти сегментов программы и об инициализации регистров процессора при загрузке программы в память.
Обратимся теперь к окну дампа. При запуске отладчика в окно дампа выводится содержимое памяти, начиная с адреса DS:0000h, т.е. начало префикса программы (см. рис. 2.4 и 2.5). Для того, чтобы вывести на экран что-либо иное, надо воспользоваться командой <Alt>+<F10>, которая для каждого внутреннего окна процессора открывает дополнительное меню. Вид этого меню зависит от того, какое окне было активным в момент ввода команды. На рис. 2.6 показано дополнительное меню окна дампа.

Рис. 2.6. Дополнительное меню окна дампа памяти.
Чаще всего приходится пользоваться первым пунктом этого меню Goto, с помощью которого можно задать любой адрес (входящий или не входящий в сегменты программы), и получить дамп этого участка.. На рис. 2.7. изображено содержимое окна дампа после ввода начального адреса в виде DS:0 (тот же результат даст начальный адрес DS:msg, а так же и просто msg, так как по умолчанию сегментный адрес берется из DS). Как и следовало ожидать, по этому адресу расположено наше единственное данное - строка текста, выводимая программой на экран. Кстати, в окне дампа видно начало промежутка между сегментами (данных и стека), заполненного нулями.

Рис. 2.7. Дамп сегмента данных.
Представление данных
В языке ассемблера имеются средства записи целых и вещественных чисел, а также символьных строк и отдельных символов. Целые числа могут быть со знаком и без знака, а также записанными в двоично-десятичном формате. Для целых чисел и символов в составе команд микропроцессора и, соответственно, в языке ассемблера, есть средства обработки - анализа, сравнения, поиска и проч. Для вещественных чисел таких средств в самом микропроцессоре нет, они содержатся в арифметическом сопроцессоре. Поскольку программирование сопроцессора в настоящей книге не рассматривается, то и вещественными числами мы заниматься не будем.
Рассмотрим сначала целые числа без знака и со знаком. Числа без знака получили свое название потому, что среди этих чисел нет отрицательных. Это самый простой вид чисел: они представляют собой весь диапазон двоичных чисел, которые можно записать в байте, слове или двойном слове. Для байта числа без знака могут принимать значения от 00h (0) до FFh (255); для слова - от 0000h (0) до FFFFh (65535); для двойного слова - от 00000000h (0) до FFFFFFFFh (4294967295).
В огромном количестве приложений вычислительной техники для чисел нет понятия знака. Это справедливо, например, для адресов ячеек памяти, кодов ASCII символов, результатов измерений многих физических величин, кодов управления устройствами, подключаемыми к компьютеру. Для таких чисел естественно использовать весь диапазон чисел, записываемых в ячейку того или иного размера. Если, однако, мы хотим работать как с положительными, так и с отрицательными числами, нам придется половину чисел из их полного диапазона считать положительными, а другую половину - отрицательными. В результате диапазон изменения числа уменьшается в два раза. Кроме того, необходимо предусмотреть систему кодирования, чтобы положительные и отрицательные числа не перекрывались.
В вычислительной технике принято записывать отрицательные числа в так называемом дополнительном коде, который образуется из прямого путем замены всех двоичных нулей единицами и наоборот (обратный код) и прибавления к полученному числу единицы. Это справедливо как для байтовых (8-битовых) чисел, так и для чисел размером в слово или в двойное слово (рис. 2.8)

Рис. 2.8. Образование отрицательных чисел различного размера.
Такой способ образования отрицательных чисел удобен тем, что позволяет выполнять над ними арифметические операции по общим правилам с получением правильного результата. Так, сложение чисел +5 и -5 дает 0; в результате вычитания 3 из 5 получается 2; вычитание -3 из -5 дает -2 и т.д.
Анализируя алгоритм образования отрицательного числа, можно заметить, что для всех отрицательных чисел характерно наличие двоичной единицы в старшем бите. Положительные числа, наоборот, имеют в старшем бите 0. Это справедливо для чисел любого размера. Кроме того, из рис. 2.8 видно, что для преобразования отрицательного 8-битового числа в слово достаточно дополнить его слева восемью двоичными единицами. Легко сообразить, что для преобразования положительного 8-битового числа в слово его надо дополнить восемью двоичными нулями. То же справедливо и для преобразования слова со знаком в двойное слово со знаком, только добавить придется уже не 8, а 16 единиц или нулей. В системе команд МП 86 и, соответственно, в языке ассемблера, для этих операций предусмотрены специальные команды cbw и cwd.
Следует подчеркнуть, что знак числа условен. Одно и то же число, например, изображенное на рис. 2.8 8-битовое число FBh можно в одном контексте рассматривать, как отрицательное (-5), а в другом - как положительное, или, правильнее, число без знака (FBh=251). Знак числа является характеристикой не самого числа, а нашего представления о его смысле.
На рис. 2.9 представлена выборочная таблица 16-битовых чисел с указанием их машинного представления, а также значений без знака и со знаком. Из таблицы видно, что для чисел со знаком размером в слово диапазон положительных значений простирается от 0 до 32767, а диапазон отрицательных значений - от -1 до -32768.

Рис. 2.9. Представление 16-битовых чисел без знака и со знаком.
На рис. 2.10 представлена аналогичная таблица для 8-битовых чисел. Из таблицы видно, что для чисел со знаком размером в байт диапазон положительных значений простирается от 0 до 127, а диапазон отрицательных значений - от -1 до -128.

Рис. 2.10. Представление 8-битовых чисел без знака и со знаком.
Среди команд процессора, выполняющих ту или иную обработку чисел, можно выделить команды, безразличные к знаку числа (например, inc, add, test), команды, предназначенные для обработки чисел без знака (mul, div, ja, jb и др.), а также команды, специально рассчитанные на обработку чисел со знаком (imul, idiv, jg, jl и т.д.). Особенности использования этих команд будут описаны в следующей главе.
Рассмотрим теперь другой вид представления чисел - двоично-десятичный формат (binary-coded decimal , BCD), используемый в ряде прикладных областей. В таком формате выдают данные некоторые измерительные приборы; он же используется КМОП-часами реального времени компьютеров IBM PC для хранения информации о текущем времени. В МП 86 предусмотрен ряд команд для обработки таких чисел.
Двоично-десятичный формат существует в двух разновидностях: упакованный и распакованный. В первом случае в байте записывается двухразрядное десятичное число от 00 до 99. Каждая цифра числа занимает половину байта и хранится в двоичной форме. Из рис. 2.11 можно заметить, что для записи в байт десятичного числа в двоично-десятичном формате достаточно сопроводить записываемое десятичное число символом h.

Рис. 2.11. Упакованный двоично-десятичный формат.
В машинном слове или в 16-разрядном регистре можно хранить в двоично-десятичном формате четырехразрядные десятичные числа от 0000 до 9999 (рис.2.12).

Рис. 2.12. Запись десятичного числа 9604 в слове.
Распакованный формат отличается от упакованного тем, что в каждом байте записывается лишь одна десятичная цифра (по-прежнему в двоичной форме). В этом случае в слове можно записать десятичные числа от 00 до 99 (см. рис. 2.13)

Рис. 2.13. Запись десятичного числа 98 в распакованном виде.
При хранении десятичных чисел в аппаратуре обычно используется более экономный упакованный формат; умножение и деление выполняются только с распакованными числами, операции же сложения и вычитания применимы и к тем, и к другим. Примеры операций с двоично-десятичными числами будут рассмотрены в следующей главе.
Описание данных
Практически любая программа содержит в себе перечень данных, с которыми она работает. Это могут быть символьные строки, предназначенные для вывода на экран; числа, определяющие ход выполнения программы или участвующие в вычислениях; адреса подпрограмм, обработчиков прерываний или просто тех или иных полей программы; специальные коды, например, коды цвета выводимых на экран символов и т.д. Кроме данных, определяемых в тексте программы, в программу часто входят зарезервированные поля, предназначенные для заполнения по ходу выполнения программы, например, результатами вычислений или путем чтения из файла. Все эти данные и зарезервированные поля должны быть определены в составе сегмента данных программы (в принципе они могут быть определены, и часто определяются, не в сегменте данных, а в сегменте команд, но здесь мы не будем касаться этого вопроса).
Для определения данных используются, главным образом, три директивы ассемблера: db (define byte, определить байт) для записи байтов, dw (define word, определить слово) для записи слов и dd (define double, определить двойное слово) для записи двойных слов:
db 255
dw 6.5535
dd 100000000
Кроме перечисленных, имеются и другие директивы, например df (define fanvord, определить поле из 6 байт), dq (define quadword, определить четверное слово) или dt (define tcraword, определить 10-байтовую переменную), но они используются значительно реже.
Для того чтобы к данным можно было обращаться, они должны иметь имена. Имена данных могут включать латинские буквы, цифры (не в качестве первого знака имени) и некоторые специальные знаки, например, знаки подчеркивания (_), доллара ($) и коммерческого at (@). Длину имени некоторые ассемблеры ограничивают (например, ассемблер MASM - 31 символом), другие - нет, но в любом случае слишком длинные имена затрудняют чтение программы. С другой стороны, имена данных следует выбирать таким образом, чтобы они отражали назначение конкретного данного, например counter для счетчика или filename для имени файла:
counter dw 10000
filename db "a:\myfile.001'
Значения числовых данных можно записывать в различных системах счисления; чаще других используются десятичная и 16-ричная запись:
size dw 256 ;В ячейку size записывается
;десятичное число 256
setb7 db 80h ;В ячейку setb7 записывается
;16-ричное число 80h
Необходимо отметить неточность приведенных выше комментариев. В памяти компьютера могут храниться только двоичные коды. Если мы говорим, что в какой-то ячейке записано десятичное число 128, мы имеем в виду не физическое содержимое ячейки, а лишь форму представления этого числа в исходном тексте программы. В слове с именем size фактически будет записан двоичный код 0000000100000000, являющийся двоичным эквивалентом десятичного числа 256. Во втором случае в байте с именем setbit? будет записан двоичный эквивалент шестнадцатиричного числа 80h, который составляет 10000000 (т.е. байт с установленным битом 7, откуда и получила имя эта ячейка).
Для резервирования места под массивы используется оператор dup (duplicate, дублировать), который позволяет "размножить" байт, слово или двойное слово заданное число раз:
rawdata dw 300 dup (1) ;Резервируются 300 слов,
;заполненных числом 1
string db 80 dup ('^') ;Резервируются 80 байтов,
;заполненных знаком '^'
Присвоение данным символических имен позволяет обращаться к ним в программных предложениях, не заботясь о фактических адресах этих данных. Например, команда
mov AX,size
занесет в регистр АХ содержимое ячейки size (число 256), независимо от того, в каком месте сегмента данных эта ячейка определена, и в какое место физической памяти она попала. Однако программист, использующий язык ассемблера, должен иметь отчетливое представление о том, каким образом назначаются адреса ячейкам программы, и уметь работать не только с символическими обозначениями, но и со значениями адресов. Для обсуждения этого вопроса рассмотрим пример сегмента данных, в котором определяются данные различных типов. В левой колонке укажем смещения данных (в шестнадцатеричной форме), вычисляемые относительно начала сегмента.
data segment
0000h counter dw 10000
0002h pages db "Страница 1"
000Ch numbers db 0, 1, 2, 3, 4
0011h page_addr dw pages
data ends
Сегмент данных начинается с данного по имени counter, которое описано, как слово (2 байт) и содержит число 10000. Очевидно, что его смещение равно 0. Поскольку это данное занимает 2 байт, следующее за ним данное pages получило смещение 2. Данное pages описывает строку текста длиной 10 символов и занимает в памяти столько же байтов, поэтому следующее данное numbers получило относительный адрес 2 + 10 = 12 = Ch. В поле numbers записаны 5 байтовых чисел, поэтому последнее данное сегмента с именем page_addr размещается по адресу Ch + 5 = 11h.
Ассемблер, начиная трансляцию сегмента (в данном случае сегмента данных) начинает отсчет его относительных адресов. Этот отсчет ведется в специальной переменной транслятора (не программы!), которая называется счетчиком текущего адреса и имеет символическое обозначение знака доллара (S). По мере обработки полей данных, их символические имена сохраняются в создаваемой ассемблером таблице имен вместе с соответствующими им значениями счетчика текущего адреса. Другими словами, введенные нами символические имена получают значения, равные их смещениям. Таким образом, с точки зрения транслятора counter равно 0, pages - 2, numbers - Ch и т.д. Поэтому предложение
page_addr dw pages
трактуется ассемблером, как
page_addr dw 2
и приводит к записи в слово с относительным адресом 11h числа 2 (смещения строки pages).
Приведенные рассуждения приходится использовать при обращении к "внутренностям" объявленных данных. Пусть, например, мы хотим выводить на экран строки "Страница 2", "Страница 3", "Страница 4" и т.д. Можно, конечно, все эти строки описать в сегменте данных по отдельности, но это приведет к напрасному расходу памяти. Экономнее поступить по-другому: выводить на экран одну и ту же строку pages, но модифицировать в ней номер страницы. Модификацию номера можно выполнить с помощью, например, такой команды:
mov pages + 9, ' 2'
Здесь мы "вручную" определили смещение интересующего нас символа в строке, зная, что все данные размещаются ассемблером друг за другом в порядке их объявления в программе. При этом, какое бы значение не получило имя pages, выражение pages + 9 всегда будет соответствовать байту с номером страницы.
Таким же приемом можно воспользоваться при обращении к данному numbers, которое в сущности представляет собой небольшой массив из 5 чисел. Адрес первого числа в этом массиве равен просто numbers, адрес второго числа - numbers + 1, адрес третьего - numbers + 2 и т.д. Следующая команда прочитает последний элемент этого массива в регистр DL:
mov DL,numbers+4
Какой смысл имело объединение ряда чисел в массив numbers? Да никакого, если к этим числам мы все равно обращаемся по отдельности. Удобнее было объявить этот массив таким образом:
nmb0 db 0
nmbl db 1
nmb2 db 2
nmb3 db 3
nmb4 db 4
В этом случае для обращения к последнему элементу не надо вычислять его адрес, а можно воспользоваться именем nmb4. Если, с другой стороны, мы хотим работать с числами, как с массивом, используя индексы отдельных элементов (о чем речь будет идти позже), то присвоение массиву общего имени представляется естественным. Получение последнего элемента массива по его индексу выполняется с помощью такой последовательности команд:
mov SI,4 ;Индекс элемента в массиве
mov DL,numbers[SI] ;Обращение по адресу
;numbers + содержимое SI
Иногда желательно обращаться к элементам массива (обычно небольшого размера) то с помощью индексов, то по их именам. Для этого надо к описанию массива, как последовательности отдельных данных, добавить дополнительное символическое описание адреса начала массива с помощью директивы ассемблера label (метка):
numbers label byte
nmb0 db 0
nmbl db 1
nmb2 db 2
nmb3 db 3
nmb4 db 4
Метка numbers должна быть объявлена в данном случае с описателем byte, так как данные, следующие за этой меткой, описаны как байты и мы планируем работать с ними именно как с байтами. Если нам нужно иметь массив слов, то отдельные элементы массива следует объявить с помощью директивы dw, а метке numbers придать описатель word:
numbers label word
nmb0 dw 0
nmbl dw 1
nmb2 dw 2
nmb3 dw 3
nmb4 dw 4
В чем состоит различие двух последних описаний данных? Различие есть, и весьма существенное. Хотя в обоих случаях в память записывается натуральный ряд чисел от 0 до 4, однако в первом варианте под каждое число в памяти отводится один байт, а во втором - слово. Если мы в дальнейшем будем изменять значения элементов нашего массива, то в первом варианте каждому числу' можно будет задавать значения от 0 до 255, а во втором - от 0 до 65535.
Выбирая для данных способ их описания, необходимо иметь в виду, что ассемблер выполняет проверку размеров используемых данных и не пропускает команды, в которых делается попытка обратиться к байтам, как к словам, или к словам - как к байтам. Рассмотрим последний вариант описания массива numbers. Хотя под каждый элемент выделено целое слово, однако реальные числа невелики и вполне поместятся в байт. Может возникнуть искушение поработать с ними, как с байтами, перенеся предварительно в байтовые регистры:
mov AL,nmb0 ;Переносим nmb0 в AL
mov DL,nmbl ;Переносим nmb1 в AL
mov CL,nmb2 ;Переносим nmb2 в AL
Так делать нельзя. Транслятор сообщит о грубой ошибке - несоответствии типов, и не будет создавать объектный файл. Однако довольно часто возникает реальная потребность в операциях такого рода. Для таких случаев предусмотрен специальный атрибутивный оператор byte ptr (byte pointer, байтовый указатель), с помощью которого можно на время выполнения одной Команды изменить размер операнда:
mov AL,byte ptr nmb0
mov DL,byte ptr nmbl
mov CL,byte ptr nmb2
Эти команды транслятор рассматривает, как правильные.
Часто возникает необходимость выполнить обратную операцию - к паре байтов обратиться, как к слову. Для этого надо использовать оператор word ptr:
okey db 'OK'
…
mov AX,word ptr okey
Здесь оба байта из байтовой переменной okey переносятся в регистр АХ. При этом первый по порядку байт, т.е. байт с меньшим адресом, содержащий букву "О" (можно считать, что он является младшим в слове
"OK"), отправится в младшую половину АХ - регистр AL, а второй по порядку байт, с буквой "К", займет регистр АН.
До сих пор речь шла о данных, которые, в сущности, являлись переменными, в том смысле, что под них выделялась память и их можно было модифицировать. Язык ассемблера позволяет также использовать константы, которые являются символическими обозначениями чисел и могут использоваться всюду в тексте программы, как наглядные эквиваленты этих чисел:
maxsize = 0FFFFh
mov CX,maxsize mov CX,0FFFFh
Последние две команды полностью эквивалентны.
При определении констант допустимо выполнение арифметических операций. Пусть нам надо задать позицию символа (или строки символов) на экране. Учитывая, что каждый символ записывается в видеопамяти в двух байтах (в первом - код ASCII символа, а во втором - его атрибут), строка экрана имеет длину 80 символов, а высота экрана составляет 25 строк, то для вывода некоторого символа в середину экрана его смещение в видеопамяти от начала видеостраницы можно определить следующим образом:
position=80*2*12+40*2
Такая запись достаточно наглядна, и ее легко модифицировать, если мы решим вывести символ в какую-то другую область экрана.
Константами удобно пользоваться для определения длины текстовых строк:
mes db 'Ждите'
mes_len = $-mes
В этом примере константа mes_len получает значение длины строки mes (в данном случае 5 байт), которая вычисляется как разность значения счетчика текущего адреса после определения строки и ее начального адреса mes. Такой способ удобен тем, что при изменении содержимого строки достаточно перетранслировать программу, и та же константа mes_len автоматически получит новое значение.
Структуры и записи
Структуры
Структуры представляют собой шаблоны с описаниями форматов данных, которые можно накладывать на различные участки памяти, чтобы затем обращаться к полям этих участков с помощью мнемонических имен, определенных в описании структуры. Структуры особенно удобны в тех случаях, когда мы обращаемся к областям памяти, не входящим в сегменты программы, т.е. к полям, которые нельзя описать с помощью символических имен. Используются структуры также и в тех случаях, когда в программе многократно повторяются сложные коллекции данных с единым строением, но различающимися значениями.
Пусть в программе, выполняющей обработку медицинской информации о пациентах, надо объявить несколько блоков данных с однородными сведениями о нескольких пациентах. Такой комплект данных удобно оформить в виде структуры, придав как всей структуре, так и составляющим се данным наглядные имена:
meddata struc ;Структура с именем meddata
index dd 0 ; Номер карты
sex db 0 ;Пол
birth dw 0 ;Год рождения
datein db ' / / ' ;Дата поступления
dateout db ' / / ' ;Дата выписки
meddata ends ;Конец описания структуры
Описание структуры можно располагать в любом месте программы, но до описания конкретных структурных переменных. Транслятор, встретившись с описанием структуры, не транслирует ее текст, т.е. не выделяет место в памяти, а просто запоминает приведенное описание, чтобы воспользоваться им в дальнейшем, если в программе встретятся объявления переменных типа этой структуры.
В сегменте данных можно объявить любое количество переменных, соответствующих по составу описанной ранее структуре, дав им произвольные имена. Эти переменные можно заполнить при их объявлении конкретными данными (разумеется, соответствующими элементам описанной ранее структуры), но можно и не указывать конкретных данных, если данную переменную предполагается инициализировать не на этапе ее объявления, а по ходу выполнения программы. В последнем случае транслятор выделяет под переменную место в памяти (в нашем примере 23 байт), заполнив ее той конкретной информацией, которая была указана в описании структуры:
data segment
pat 1 meddata <1234567, 'м',1955, 1З/06/981, '15/06/98'>
pat2 meddata <1982234, 'м',1932, '18/06/98', '25/06/98 '>
pat3 meddata <4389012, 'ж',1966, '01/12/97', '15/12/97'>
pattemp meddata <>
data ends
Имена patl, pat2 и т.д. будут служить именами переменных, каждая из которых содержит полный комплект данных об одном пациенте. Угловые скобки ограничивают конкретные данные, поступающие в каждую структурную переменную. Для переменной с именем pattemp транслятор выделит в памяти 23 байт, поместив в нее в точности то, что было указано в описании структуры (нули и два символьные шаблона для даты):
0,0,0, ' / / ',' / / '
При обработке данных в программе можно пользоваться мнемоническими обозначениями всей структуры и ее составляющих, причем имена элементов структуры должны отделяться точкой:
mov EAX,patl.index ;ЕАХ=1234567
mov SI,offset patl.datein ;31=смещение элемента patl.datein
mov DL,pat3.sex ;DL='ж'
Особенности использования в приложениях DOS 32-разрядных регистров (ЕАХ в первой строке приведенного фрагмента) будут описаны в гл. 4.
Адрес конкретной структурной переменной можно поместить в базовый или индексный регистр, и пользоваться им в конструкциях с косвенной адресацией:
mov BX,offset pat3 ;ВХ=смещение pat3
mov EAX,[BX].index ;EAX=4389012
mov [BX].sех='м' ;Программная инициализация
Имена элементов структуры являются, в сущности, смещениями к этим элементам от начала структуры. В некоторых случаях их можно использовать в этом качестве и без предваряющей точки:
mov BX, off set pat2 ;ВХ=смещение pat2
add BX,sex ;ВХ=смещение pat2.sex
mov DL, [BX] ;DL='M'
mov SI,birth ;SI=5 (сомнительная команда)
Записи
Записи, как и структуры, представляют собой шаблоны, накладываемые на реальные данные с целью введения удобных мнемонических обозначений отдельных элементов данных. В отличие от структур, дающих имена байтам, словам, двойным словам или целым массивам, в записях определяются строки битов внутри байтов, слов или двойных слов.
Известно, что дата создания файла хранится в каталоге диска в виде 16-битового слова, в котором старшие 7 бит обозначают год (от 1980), следующие 4 бит - месяц и последние 5 бит - день (рис. 2.14).

Рис. 2.14. Формат записи даты в каталоге диска.
Эти данные удобно специфицировать с помощью записи filedate, определяемой в программе следующим образом:
fdate record year:7, month: 4, day:5
Ключевое слово record говорит о том, что имя fdate относится к записи, а мнемонические обозначения year, month и day являются произвольными именами отдельных битовых полей описываемого слона.
Включение в программу описания шаблона битовых полей позволяет отказаться от утомительного и чреватого ошибками определения "вручную" содержимого полного данного по задаваемым значениям его отдельных составляющих. Для приведенной выше записи объявления конкретных переменных будут выглядеть следующим образом:
filel fdate <5,6,7> ;7 июня 1985г.
file2 fdate <18,12,30> ;30 декабря 1998г.
file3 fdate <> ;"Пустая" (пока) переменная
Переменная filel будет определена, как число 0AC7h, file2 - как число 259Eh, а fileЗ - как число 0000h. При необходимости программного заполнения переменной типа fdate можно пользоваться именами ее составляющих, которые трактуются ассемблером, как индексы соответствующих битовых полей, отсчитываемые от младшего конца слова. Для приведенного примера day=0, month=5, a year=9. Однако в системе команд МП 86 практически нет средств работы с битовыми полями. Поэтому программное заполнение придется осуществлять с помощью команд сдвигов и логического сложения:
mov flle3,30 ;Помещаем день
mov AX,12 ;Месяц пока в АХ
mov CL,month ;Будем сдвигать на month бит
shl AX,CL ; Сдвинули месяц в АХ на 5 бит
or file3,AX ;Добавили биты месяца в file3
mov AX, 18 ;Год пока в АХ
mov CL,month ;Будем сдвигать на year бит
shl AX,CL ;Сдвинули год в АХ на 9 бит
or file3,AX ;Добавили биты года в file3
В итоге в переменной fileЗ окажется тот же код 259Eh, что и в переменной file2.
Способы адресации
Способом, или режимом адресации называют процедуру нахождения операнда для выполняемой команды. Если команда использует два операнда, то для каждого из них должен быть задан способ адресации, причем режимы адресации первого и второго операнда могут как совпадать, так и различаться. Операнды команды могут находиться в разных местах: непосредственно в составе кода команды, в каком-либо регистре, в ячейке памяти; в последнем случае существует несколько возможностей указания его адреса. Строго говоря, способы адресации являются элементом архитектуры процессора, отражая заложенные в нем возможности поиска операндов. С другой стороны, различные способы адресации определенным образом обозначаются в языке ассемблера и в этом смысле являются разделом языка.
Следует отметить неоднозначность термина "операнд" применительно к программам, написанным на языке ассемблера. Для машинной команды операндами являются те данные (в сущности, двоичные числа), с которыми она имеет дело. Эти данные могут, как уже отмечалось, находиться в регистрах или в памяти. Если же рассматривать команду языка ассемблера, то для нее операндами (или, лучше сказать, параметрами) являются те обозначения, которые позволяют сначала транслятору, а потом процессору определить местонахождение операндов машинной команды. Так, для команды ассемблера
mov mem, AX
в качестве операндов используется обозначение ячейки памяти mem, a также обозначение регистра АХ. В то же время, для соответствующей машинной команды операндами являются содержимое ячейки памяти и содержимое регистра. Было бы правильнее говорить об операндах машинных команд и о параметрах, или аргументах команд языка ассемблера.
По отношению к командам ассемблера было бы правильнее использовать термин "параметры", оставив за термином "операнд" обозначение тех физических объектов, с которыми имеет дело процессор при выполнении машинной команды, однако обычно эти тонкости не принимают в расчет, и говоря об операндах команд языка, понимают в действительности операнды машинных команд.
В архитектуре современных 32-разрядных процессоров Intel предусмотрены довольно изощренные способы адресации; в МП 86 способов адресации меньше. В настоящем разделе будут описаны режимы адресации, используемые в МП 86.
В книгах, посвященных языку ассемблера, можно встретить разные подходы к описанию способов адресации: не только названия этих режимов, но даже и их количество могут различаться. Разумеется, способов адресации существует в точности столько, сколько их реализовано в процессоре; однако, режимы адресации можно объединять в группы по разным признакам, отчего и создается некоторая путаница, в том числе и в количестве имеющихся режимов. Мы будем придерживаться распространенной, но не единственно возможной терминологии.
Регистровая адресация. Операнд (байт или слово) находится в регистре. Этот способ адресации применим ко всем программно-адресуемым регистрам процессора.
inc СН ;Плюс 1 к содержимому СН
push DS ;DS сохраняется в стеке
xchg ВХ,ВР ;ВХ и ВР обмениваются содержимым
mov ES, АХ ;Содержимое АХ пересылается в ES
Непосредственная адресация. Операнд (байт или слово) указывается в команде и после трансляции поступает в код команды; он может иметь любой смысл (число, адрес, код ASCII), а также быть представлен в виде символического обозначения.
mov АН, 40h ;Число 40h загружается в АН
mov AL,'*' ;Код ASCII символа "*' загружается в AL
int 21h ;Команда прерывания с аргументом 21h
limit = 528 ;Число 528 получает обозначение limit
mov CX,limit ;Число, обозначенное limit, загружается в СХ
Команда mov, использованная в последнем предложении, имеет два операнда; первый операнд определяется с помощью регистровой адресации, второй - с помощью непосредственной.
Важным применением непосредственной адресации является пересылка относительных адресов (смещений). Чтобы указать, что речь идет об относительном адресе данной ячейки, а не об ее содержимом, используется описатель onset (смещение):
; Сегмент данных
mes db "Урок 1' ;Строка символов
;Сегмент команд
mov DX,offset mes ;Адрес строки засылается в DX
В приведенном примере относительный адрес строки mes, т.е. расстояние в байтах первого байта этой строки от начала сегмента, в котором она находится, заносится в регистр DX.
Прямая адресация памяти. Адресуется память; адрес ячейки памяти (слова или байта) указывается в команде (обычно в символической форме) и поступает в код команды:
;Сегмент данных
meml dw 0 ;Слово памяти содержит 0
mem2 db 230 ;Байт памяти содержит 230
;Сегмент команд
inc meml ;Содержимое слова meml увеличивается на 1
mov DX, meml ; Содержимое слова с именем menu загружается в DX
mov AL,mem2 ; Содержимое байта с именем mem2 загружается в АL
Сравнивая этот пример с предыдущим, мы видим, что указание в команде имени ячейки памяти обозначает, что операндом является содержимое этой ячейки; указание имени ячейки с описателем offset - что операндом является адрес ячейки.
Прямая адресация памяти на первой взгляд кажется простой и наглядной. Если мы хотим обратиться, например, к ячейке meml, мы просто указываем ее имя в программе. В действительности, однако, дело обстоит сложнее. Вспомним, что адрес любой ячейки состоит из двух компонентов: сегментного адреса и смещения. Обозначения meml и mem2 в предыдущем примере, очевидно, являются смещениями. Сегментные же адреса хранятся в сегментных регистрах. Однако сегментных регистров четыре: DS, ES, CS и SS. Каким образом процессор узнает, из какого регистра взять сегментный адрес, и как сообщить ему об этом в программе?
Процессор различает группу кодов, носящих название префиксов. Имеется несколько групп префиксов: повторения, размера адреса, размера операнда, замены сегмента. Здесь нас будут интересовать префиксы замены сегмента.
Команды процессора, обращающиеся к памяти, могут в качестве первого байта своего кода содержать префикс замены сегмента, с помощью которого процессор определяет, из какого сегментного регистра взять сегментный адрес. Для сегментного регистра ES код префикса составляет 26h, для SS - 361i, для CS - 2Eh. Если префикс отсутствует, сегментный адрес берется из регистра DS (хотя для него тоже предусмотрен свой префикс).
Если в начале программы с помощью директивы assume указано соответствие сегменту данных сегментного регистра DS
assume DS:data
то команды обращения к памяти транслируются без какого-либо префикса, а процессор при выполнении этих команд берет сегментный адрес из регистра DS.
Если в директиве assume указано соответствие сегмента данных регистру ES
assume ES:data
(в этом случае сегмент данных должен располагаться перед сегментом команд), то команды обращения к полям этого сегмента транслируются с добавлением префикса замены для сегмента ES. При этом предложения программы выглядят обычным образом; в них по-прежнему просто указываются имена полей данных, к которым производится обращение.
Однако в ряде случаев префикс замены сегмента должен указываться в программе в явной форме. Такая ситуация возникает, например, если данные расположены в сегменте команд, что типично для резидентных обработчиков прерываний. Для обращения к таким данным можно, конечно, использовать регистр DS, если предварительно настроить его на сегмент команд, но проще выполнить адресацию через регистр CS, который и так уже настроен должным образом. Если в сегменте комавд содержится поле данных с именем mem, то команда чтения из этого поля будет выглядеть следующим образом:
mov AX,CS:mem
В этом случае транслятор включит в код команды префикс замены для сегмента CS. Другие примеры команд с заменой сегмента будут приведены ниже.
До сих пор мы обсуждали адресацию ячеек, содержащихся в сегментах данных программы. Однако часто бывает нужно обратиться к памяти вне пределов программы: к векторам прерываний, системным таблицам, видеобуферу и т.д. Разумеется, такое обращение возможно только если мы знаем абсолютный адрес интересующей нас ячейки. В этом случае необходимо сначала настроить один из сегментных регистров на начато интересующей нас области, после чего можно адресоваться к ячейкам по их смещениям.
Пусть требуется вывести в левый верхний угол экрана несколько символов, например, два восклицательных знака. Эту операцию можно реализовать с помощью следующих команд:
mov AX,0B800h ;Сегментный адрес видеобуфера
mov ES,AX ;Отправим его в ES
mov byte ptr ES:0, ' ! ' ;Отправим символ на 1-е знакоместо экрана
mov byte ptr ES:2, ' ! ' ;Отправим символ на 2-е знакоместо экрана
Настроив регистр ES на сегментный адрес видеобуфера BS00h, мы пересылаем код знака "!" сначала по относительному адресу 0 (в самое начало видеобуфера, в байт со смещением 0), а затем на следующее знакоместо, имеющее смещение 2 (в нечетных байтах видеобуфера хранятся атрибуты символов, т.е. цвет символов и фона под ними). В обеих командах необходимо с помощью обозначения ES: указать сегментный регистр, который используется для адресации памяти. Встретившись с этим обозначением, транслятор включит в код команды префикс замены сегмента, в данном случае код 26h.
В приведенном примере мы снова столкнулись с использованием атрибутивного оператора byte ptr, который позволяет в явной форме задать размер операнда. Однако если раньше этот оператор использовался, чтобы извлечь байт из данного, объявленного, как слово, то здесь его назначение иное. Транслятор, обрабатывая команду
mov byte ptr ES:0, ' ! '
не имеет возможности определить размер операнда-приемника. Разумеется, видеобуфер, как и любая память, состоит из байтов, однако надо ли рассматривать эту память, как последовательность байтов или слов? Команда без явного задания размера операнда
mov ES:0, ' ! '
вызовет ошибку трансляции, так как ассемблер не сможет определить, надо ли транслировать это предложение, как команду пересылки в видеобуфер байта 21h, или как команду пересылки слова 0021h.
Между прочим, на первый взгляд может показаться, что в обсуждаемой команде достаточно ясно указан размер правого операнда, так как символ (в данном случае "!") всегда занимает один байт. Однако транслятор, встретив обозначение "!", сразу же преобразует его в код ASCII этого символа, т.е. в число 21h, и уже не знает, откуда это число произошло и какой размер оно имеет.
Стоит еще отметить, что указание в команде описателя word ptr
mov word ptr ES:0,'!'
не вызовет ошибки трансляции, но приведет к неприятным результатам. В этом случае в видеобуфер будет записано слово 002lh, которое заполнит байт 0 видеобуфера кодом 21h, а байт 1 кодом 00h. Однако атрибут 00h обозначает черный цвет на черном фоне, и символ на экране виден не будет (хотя и будет записан в видеобуфер).
При желании можно избавиться от необходимости вводить описатель размера операнда. Для этого надо пересылать не непосредственное данное, а содержимое регистра:
mov AL,'!' mov ES:0,AL
Здесь операндом- источником служит регистр AL, размер которого (1 байт) известен, и размер операнда-приемника определять не надо. Разумеется, команда
mov ES:0,AX
заполнит в видеобуфере не байт, а слово.
Для адресации к видеобуферу в вышеприведенном примере использовался сегментный регистр дополнительных данных ES. Это вполне естественно, так как обычно регистр DS служит для обращения к полям данных программы, а регистр ES как раз и предназначен для адресации всего остального. Однако при необходимости можно было воспользоваться для записи в видеобуфер регистром DS:
mov AX,0B800h ;Сегментный адрес
mov DS,AX ; видеобуфера в DS
mov byte ptr DS:0, ' ! ' ;Символ в видеобуфер
Любопытно, что хотя обозначение DS: здесь необходимо, транслятор не включит в код команды префикс замены сегмента, так как команда без префикса выполняет адресацию по умолчанию через DS.
Если, однако, по умолчанию выполняется адресация через DS, то нельзя ли опустить в последней команде обозначение сегментного регистра? Нельзя, так как обозначение DS: число указывает, что число является не непосредственным операндом, а адресом операнда. Команда (неправильная)
mov 6,10
должна была бы переслать число 10 в число 6, что, разумеется, лишено смысла и выполнено быть не может. Команда же
mov DS:6,10
пересылает число 10 по относительному адресу 6, что имеет смысл. Таким образом, обозначение сегментного регистра с двоеточием перед операндом говорит о том, что операнд является адресом. В дальнейшем мы еще столкнемся с этим важным правилом.
Мы рассмотрели три важнейших способа адресации: регистровую, непосредственную и прямое обращение к памяти. Все остальные режимы адресации относятся к группе косвенной адресации памяти, когда в определении адреса ячейки памяти участвует один или несколько регистров процессора. Рассмотрим последовательно эти режимы.
Регистровая косвенная (базовая и индексная). Адресуется память (байт или слово). Относительный адрес ячейки памяти находится в регистре, обозначение которого заключается в прямые скобки. В МП 86 косвенная адресация допустима только через регистры ВХ, ВР, SI и DI. При использовании регистров ВХ или ВР адресацию называют базовой, при использовании регистров SI или DI - индексной.
Преобразуем приведенный выше пример, чтобы продемонстрировать использование косвенной адресации через регистр.
mov AX,0B800h ;Сегментный адрес
mov ES,AX ; видеобуфера в ES
mov BX,2000 ;Смещение к середине экрана
mov byte ptr ES:[ВХ], ' ! ' ;Символ на экран
Настроив ES, мы засылаем в регистр ВХ требуемое смещение (для разнообразия к середине видеобуфера, который имеет объем точно 4000 байт), и в последней команде засылаем код в видеобуфер с помощью косвенной базовой адресации через пару регистров ES:BX с указанием замены сегмента (ES:).
Если косвенная адресация осуществляется через один из регистров ВХ, SI или DI, то подразумевается сегмент, адресуемый через DS, поэтому при адресации через этот регистр обозначение DS: можно опустить:
mov AX,0B800h ;Сегментный адрес
mov DS,AX ;видеобуфера в DS
mov BX,2000 ;Смещение к середине экрана
mov byte ptr [ВХ], ' ! ' ;Символ на экран
Кстати, этот фрагмент немного эффективнее предыдущего в смысле расходования памяти. Из-за отсутствия в коде последней команды префикса замены сегмента он занимает на 1 байт меньше места.
Регистры ВХ, SI и DI в данном применении совершенно равнозначны, и с одинаковым успехом можно воспользоваться любым из них:
mov D1,2000 ;Смещение к середине экрана
mov byte ptr [DI] , ' ! ' ;Символ на экран
Не так обстоит дело с регистром ВР. Этот регистр специально предназначен для работы со стеком, и при адресации через этот регистр в режимах косвенной адресации подразумевается сегмент стека; другими словами, в качестве сегментного регистра по умолчанию используется регистр SS.
Обычно косвенная адресация к стеку используется в тех случаях, когда необходимо обратиться к данным, содержащимся в стеке, без изъятия их оттуда (например, если к эти данные приходится считывать неоднократно). Пример такого рода операций будет приведен при обсуждении следующего режима адресации.
Сравнивая приведенные выше фрагменты программ, можно заметить, что использование базовой адресации, на первый взгляд, снижает эффективность программы, так как требует дополнительной операции - загрузки в базовый регистр требуемого адреса. Действительно, базовая адресация в нашем примере не оправдана - в случае прямого обращения к памяти вместо двух команд
mov BX,2000 ;Смещение к середине экрана
mov byte ptr ES: [BX] , ' ! ' ;Символ на экран
можно использовать одну
mov byte ptr ES:2000,'!' ;Выведем символ в середину экрана
Однако команда с базовой адресацией занимает меньше места в памяти (так как в нее не входит адрес ячейки) и выполняется быстрее команды с прямой адресацией (из-за того, что команда короче, процессору требуется меньше времени на ее считывание из памяти). Поэтому базовая адресация эффективна в тех случаях, когда по заданному адресу приходится обращаться многократно, особенно, в цикле. Выигрыш оказывается тем больше, чем большее число раз происходит обращение по указанному адресу. С другой стороны, возможности этого режима адресации невелики, и на практике чаще используют более сложные способы, которые будут рассмотрены ниже.
Регистровая косвенная адресация со смещением (базовая и индексная). Адресуется память (байт или слово). Относительный адрес операнда определяется, как сумма содержимого регистра BX, BP, SI или DI и указанной в команде константы, иногда называемой смещением. Смещение может быть числом или адресом. Так же, как и в случае базовой адресации, при использовании регистров BX, SI и DI подразумевается сегмент, адресуемый через DS, а при использовании ВР подразумевается сегмент стека и, соответственно, регистр SS.
Рассмотрим применение косвенной адресации со смещением на примере прямого вывода в видеобуфер.
mov AX,0B800h ;Сегментный адрес
mov ES,AX ;видеобуфера в ES
mov DI, 80*2*24 ;Смещение к нижней строке экрана
mov byte ptr ES: [DI] ,'О' ;Символ на экран
mov byte ptr ES:2[DI],'К' ;Запишем символ в следующую позицию
mov byte ptr ES:4[DI],' ! ' ;Запишем символ в следующую позицию
В этом примере в качестве базового выбран регистр DI; в него заносится базовый относительный адрес памяти, в данном случае смещение в видеобуфере к началу последней строки экрана. Модификация этого адреса с целью получить смещение по строке экрана осуществляется с помощью констант 2 и 4, которые при вычислении процессором исполнительного адреса прибавляются к содержимому базового регистра DI.
Иногда можно встретиться с альтернативными обозначениями того же способа адресации, которые допускает ассемблер. Вместо, например, 4[ВХ] можно с таким же успехом написать [ВХ+4], 4+[ВХ] или [ВХ]+4. Такая неоднозначность языка ничего, кроме путаницы, не приносит, однако ее надо иметь в виду, так как с этими обозначениями можно столкнуться, например, рассматривая текст деассемблированной программы.
Рассмотрим теперь пример использования базовой адресации со смещением при обращении к стеку:
;Основная программа
push DS ;В стек загружаются значения
push ES ;трех регистров,
push SI ;передаваемых подпрограмме
call mysub ;Вызов подпрограммы mysub,
;использующей эти параметры
;Подпрограмма mysub
mov BP,SP ;Поместим в ВР текущий адрес вершины стека
mov АХ,2[ВР], ;Читаем в АХ последний параметр (SI)
mov ВХ,4[ВР] ;Читаем в ВХ предыдущий параметр (ES)
mov CX,6[BP] ;Читаем в СХ первый параметр (DS)
Здесь продемонстрирован классический прием чтения содержимого стека без извлечения из него этого содержимого. После того, как основная, программа сохранила в стеке три параметра, которые потребуются подпрограмме, командой call вызывается подпрограмма mysub. Эта команда сохраняет в стеке адрес возврата (адрес следующего за call предложения основной программы) и осуществляет переход на подпрограмму. Состояние стека при входе в подпрограмму приведено на рис. 2.15.

Рис.2.15. Состояние стека после загрузки в него трех параметров и перехода на подпрограмму
Если бы подпрограмма просто сняла со стека находящиеся там параметры, она первым делом изъяла бы из стека адрес возврата, и лишила бы себя возможности вернуться в основную программу (подробнее вопросы вызова подпрограммы и возврата из нее будут обсуждаться в последующих разделах). Поэтому в данном случае вместо команд pop удобнее воспользоваться командами mov. Подпрограмма копирует в ВР содержимое трех параметров и перехода на мое SP и использует затем этот адрес в качестве базового, модифицируя его с помощью базовой адресации со смещением.
Кстати, мы опять сталкиваемся здесь с той весьма обычной ситуацией, когда программист не имеет возможности обращаться по наглядным символическим адресам, которых в стеке, естественно, нет, а вынужден определять "вручную" смещения к интересующим его элементам стека. При этом необходимо учесть и алгоритм выполнения команды call, которая, сохраняя в стеке адрес возврата в основную программу, смещает указатель стека еще на одно слово.
В нашем фрагментарном примере мы не рассматриваем вопрос возврата в основную программу. Вдумчивый читатель мог также усомниться в правильности или, лучше сказать, в разумности текста подпрограммы. Ведь перенося параметры из стека в регистры общего назначения, подпрограмма затирает их исходное содержимое. Если же они не содержали ничего нужного, то ими можно было воспользоваться для передачи параметров в подпрограмму, а не связываться с мало наглядными операциями со стеком. Действительно, ради краткости мы опустили операции, практически необходимые в любой подпрограмме - сохранение в стеке (опять в стеке!) тех регистров, которые будут использоваться в подпрограмме. Кстати, это относится и к регистру ВР. В реальной подпрограмме эти действия следовало выполнить, что привело бы к изменению смещений при регистре ВХ, которые приняли бы значения (с учетом сохранения 4 регистров) 10, 12 и 14.
Во всех приведенных выше примерах регистр использовался для хранения базового адреса, а смещение, если оно требовалось, указывалось в виде константы. Возможна и обратная ситуация, когда в качестве смещения выступает адрес массива, а в регистре находится индекс адресуемого элемента в этом массиве. Рассмотрим относительно реальный пример такого рода.
Пусть нам надо заполнить массив из 10000 слов натуральным рядом чисел. Зарезервируем в сегменте данных место под этот массив, а в сегменте команд организуем цикл занесения в последовательные слова массива ряда нарастающих чисел. Нам придется воспользоваться несколькими новым командами (inc, add и loop), которые в дальнейшем будут рассмотрены более подробно.
;Сегмент данных
array dw 10000
;Сегмент команд
mov SI, 0 ;Начальное значение индекса элемента в массиве
mov АХ, 0 ;Первое число-заполнитель
mov СХ,10000;Число шагов в цикле (всегда в СХ)
fill: mov array[SI],AX ;Занесение числа в элемент массива
inc AX ;Инкремент числа-заполнителя
add SI,2 ;Смещение в массиве к следующему слову
loop fill ;Возврат на метку fill (СХ раз)
Цикл начинается с команды, помеченной меткой fill (правила образования имен меток такие же, как и для имен полей данных). В этой команде содержимое АХ, поначалу равное 0, переносится в ячейку памяти, адрес которой вычисляется, как сумма адреса массива array и содержимого индексного регистра SI, в котором в первом шаге никла тоже 0. В результате в первое слово массива заносится 0. Далее содержимое регистра АХ увеличивается на 1, содержимое регистра SI - на 2 (из-за того, что массив состоит из слов), и командой loop осуществляется переход на метку fill, после чего тело цикла повторяется при новых значениях регистров АХ и SI. Число шагов в цикле, отсчитываемое командой loop, определяется исходным содержимым регистра СХ.
Базово-индексная адресация. Адресуется память (байт или слово). Относительный адрес операнда определяется, как сумма содержимого следующих пар регистров:
[ВХ] [SI] (подразумевается DS:[BX][SI])
[ВХ][DI] (подразумевается DS:[BX][DI])
[ВР] [SI] (подразумевается SS:[BP][SI])
[ВР] [DI] (подразумевается SS:[BP][DI])
Это чрезвычайно распространенный способ адресации, особенно, при работе с массивами. В нем используются два регистра, при этом одним из них должен быть базовый (ВХ или ВР), а другим - индексный (SI или DI). Как правило, в одном из регистров находится адрес массива, а в другом - индекс в нем, при этом совершенно безразлично, в каком что. Трансформируем предыдущий пример, введя в него более эффективную базово-индексную адресацию.
;Сегмент данных
array dw 10000
;Сегмент команд
mov BX,offset array ;Базовый адрес массива в
;базовом регистре
mov SI, 0 ;Начальное значение индекса
;элемента в массиве
mov АХ, 0 ;Первое число-заполнитель
mov CX,10000 ;Число шагов в цикле
fill: mov [BX][SI],AX ;Отправим число в массив
inc AX ;Инкремент числа-заполнителя
add SI, 2 ;Смещение в массиве к следующему слову
loop fill ;На метку fill (CX раз)
Повышение эффективности достигается за счет того, что команда занесения числа в элемент массива оказывается короче (так как в нее не входит адрес массива) и выполняется быстрее, так как этот адрес не надо каждый раз считывать из памяти.
Базово-индексная адресация со смещением. Адресуется память (байт или слово). Относительный адрес операнда определяется как сумма содержимого двух регистров и смещения.
Это способ адресации является развитием предыдущего. В нем используются те же пары регистров, но полученный с их помощью результирующий адрес можно еще сместить на значение указанной в команде константы. Как и в случае базово-индексной адресации, константа может представлять собой индекс (и тогда в одном из регистров должен содержаться базовый адрес памяти), но может быть и базовым адресом. В последнем случае регистры могут использоваться для хранения составляющих индекса. Приведем формальный пример рассматриваемого режима адресации.
Пусть в сегменте данных определен массив из 24 байтов, в котором записаны коды латинских и русских символов верхнего ряда клавиатуры:
sims db "QWERTYUIOP{}'
db "ЙЦУКЕНПШЦЗХЪ'
Последовательность команд
mov BX,12 ;Число байтов в строке
mov SI, 6
mov DL,syms[BX][SI]
загрузит в регистр DL элемент с индексом 6 из второго ряда, т.е. код ASCII буквы Г. Тот же результат можно получить, загрузив в один из регистров не индекс, а адрес массива:
mov BX, off set sym
mov SI,6
mov DL, 12 [BX] [SI]
Переходы
Как уже отмечалось в гл. 1, присущий процессору алгоритм выполнения программы заставляет его выполнять команды программы друг за другом, в том порядке, как они были описаны в исходном тексте программы и содержатся в выполнимом модуле. Однако часто программисту требуется нарушить этот порядок, заставив процессор обойти некоторый участок программы, перейти на выполнение другой ветви или передать управление подпрограмме, имея в виду после ее завершения вернуться на прежнее место. Все эти операции осуществляются с помощью команд переходов. Переходы разделяются на безусловные, когда передача управления в другую точку программы осуществляется в безусловном порядке, независимо ни от каких обстоятельств, и условные, осуществляемые или не осуществляемые в зависимости от тех или иных условий: результатов сравнения, анализа, поиска и т.п. Безусловные переходы подразделяются на собственно переходы (без возврата в точку перехода) и вызовы подпрограмм (с возвратом после завершения подпрограммы).
Операции переходов и вызовов подпрограмм, помимо их практической ценности, представляют значительный методический интерес, так как затрагивают основу архитектуры процессора - сегментную адресацию памяти. Многочисленные разновидности команд переходов и вызовов обязаны своим существованием не столько потребностям практического программирования, сколько принципиальным архитектурным особенностям процессора. Отчетливое понимание этих особенностей и, соответственно, условий применения и возможностей различных операций переходов необходимо не только при использовании языка ассемблера, но и при программировании на языках высокого уровня, где иногда используется несколько иная терминология, но существо дела остается без изменения.
Безусловные переходы осуществляются с помощью команды jmp, которая может использоваться в 5 разновидностях. Переход может быть:
прямым коротким (в пределах -128... + 127 байтов);
прямым ближним (в пределах текущего сегмента команд):
прямым дальним (в другой сегмент команд);
косвенным ближним (в пределах текущего сегмента команд через ячейку
с адресом перехода);
косвенным дальним (в другой сегмент команд через ячейку с адресом
перехода).
Рассмотрим последовательно структуру программ с переходами разного вида.
Прямой короткий (short) переход. Прямым называется переход, в команде которого в явной форме указывается метка, на которую нужно перейти. Разумеется, эта метка должна присутствовать в том же программном сегменте, при этом помеченная ею команда может находиться как до, так и после команды jmp. Достоинство команды короткого перехода заключается в том, что она занимает лишь 2 байт памяти: в первом байте записывается код операции (EBh), во втором - смещение к точке перехода. Расстояние до точки перехода отсчитывается от очередной команды, т.е. команды, следующей за командой jmp. Поскольку требуется обеспечить переход как вперед, так и назад, смещение рассматривается, как число со знаком и, следовательно, переход может быть осуществлен максимум на 127 байт вперед или 128 байт назад. Прямой короткий переход оформляется следующим образом:
code segment
…
jmp short go ;Код ЕВ dd
go:
…
code ends
Если программа транслируется ассемблером TASM, и в строке вызова транслятора указано, что трансляцию следует выполнить в два прохода
tasm /m2 p,p,p
то описатель short можно опустить, так как ассемблер сам определит, что расстояние до точки перехода укладывается в короткий переход, даже если метка go расположена после строки с командой jmp. При использовании транслятора MASM указание описателя short обязательно (если метка go расположена после команды jmp). Здесь проявляются незначительные различия ассемблеров разных разработчиков.
В комментарии указан код команды; dd (от displacement, смещение) обозначает байт со смещением к точке перехода от команды, следующей за командой jmp.
При выполнении команды прямого короткого перехода процессор прибавляет значение байта dd к младшему байту текущего значения указателя команд IP (который, как уже говорилось, всегда указывает на команду, следующую за выполняемой). В результате в IP оказывается адрес точки перехода, а предложения, находящиеся между командой jmp и точкой перехода, не выполняются. Между прочим, конструкция с прямым переходом вперед часто используется для того, чтобы обойти данные, которые по каким-то причинам желательно разместить в сегменте команд.
Прямой ближний (near), или внутрисегментный переход. Этот переход отличается от предыдущего только тем, что под смещение к точке перехода отводится целое слово. Это дает возможность осуществить переход в любую точку 64-кбайтного сегмента.
code segment
…
jmp go ;Код Е9 dddd
…
go:
…
code ends
Метка go может находиться в любом месте сегмента команд, как до, так и после команды jmp. В коде команды dddd обозначает слово с величиной относительного смещения к точке перехода от команды, следующей за командой jmp.
При выполнении команды прямого ближнего перехода процессор должен прибавить значение слова dddd к текущему значению указателя команд IP и сформировать тем самым адрес точки перехода. Что представляет собой смещение ddddl Какая это величина, со знаком или без знака? Если рассматривать смещение как величину без знака, то переход будет возможен только вперед, что, конечно, неверно. Если же смещение является величиной со знаком, то переход возможен не более, чем на полсегмента вперед или на полсегмента назад, что тоже неверно. В действительности, рассматривая вычисление адреса точки перехода, следует иметь в виду явление оборачивания, суть которого можно кратко выразить такими соотношениями:
FFFFh+0001h=0000h
0000h-0001h=FFFFh
Если последовательно увеличивать содержимое какого- либо регистра или ячейки памяти, то, достигнув верхнего возможного предела FFFFh, число "перевалит" через эту границу, станет равным нулю и продолжит нарастать в области малых положительных чисел (1, 2, 3, и т.д.). Точно так же, если последовательно уменьшать некоторое положительное число, то оно, достигнув нуля, перейдет в область отрицательных (или, что то же самое, больших беззнаковых) чисел, проходя значения 2, 1, 0, FFFFh, FFFEh и т.д.
Таким образом, при вычислении адреса точки перехода смещение следует считать числом без знака, но при этом учитывать явление оборачивания. Если команда jmp находится где-то в начале сегмента команд, а смещение имеет величину порядка 64 К, то переход произойдет вперед, к концу сегмента. Если же команда находится в конце сегмента команд, а смещение имеет ту же величину порядка 64 К, то для определения точки перехода надо двигаться по сегменту вперед, дойти до его конца и продолжать перемещаться от начала сегмента по-прежнему вперед, пока не будет пройдено заданное в смещении число байтов. Для указанных условий мы попадем в точку, находящуюся недалеко от команды jmp со стороны меньших адресов.
Итак, с помощью команды ближнего перехода (команда jmp без каких-либо спецификаторов) можно перейти в любую точку в пределах данного сегмента команд. Для того, чтобы перейти в другой сегмент команд, следует воспользоваться командой дальнего перехода.
Прямой дальний (far), или межсегментный переход. Этот переход позволяет передать управление в любую точку любого сегмента. При этом, очевидно, предполагается, что программный комплекс включает несколько сегментов команд. Команда дальнего перехода имеет длину 5 байт и включает, кроме кода операции EAh, еще и полный адрес точки перехода, т.е. сегментный адрес и смещение. Транслятору надо сообщить, что этот переход - дальний (по умолчанию команда jmp транслируется, как команда ближнего перехода). Это делается с помощью описателя far ptr, указываемого перед именем точки перехода.
codel segment
assume CS: codel ; Сообщим транслятору, что это сегмент команд
…
jmp far ptr go ;Код EA dddd ssss
…
codel ends
code2 segment
assume CS : code2 ; Сообщим транслятору, что это сегмент команд
…
gо:
…
code2 ends
Метка go находится в другом сегменте команд этой двухсегментной программы. В коде команды ssss - сегментный адрес сегмента code2, a dddd - смещение точки перехода go в сегменте команд code2.
Заметим, что при наличии в программе нескольких сегментов команд, каждый из них необходимо предварять директивой ассемблера assume СS:имя_сегмента, которая сообщает транслятору о том, что начался очередной сегмент команд. Это поможет транслятору правильно обрабатывать адреса меток, встречающихся в этом сегменте.
Освоив применение команд дальних переходов, мы получили возможность создавать программы любой длины. Действительно, предусмотрев в конце каждого программного сегмента команду дальнего перехода на начато следующего, мы можем включить в программный комплекс любое число сегментов по 64 Кбайт. Единственное ограничение - чтобы они все поместились в памяти. В действительности так, конечно, не делают. Разумнее дополнительные сегменты команд заполнить подпрограммами и вызывать их из основного сегмента (или друг из друга) по мере необходимости. Однако и в этом случае команды вызовов подпрограмм должны быть дальними. Разновидности подпрограмм и команд их вызова будут рассмотрены ниже.
Все виды прямых переходов требуют указания в качестве точки перехода программной метки. С одной стороны, это весьма наглядно; просматривая текст программы, можно сразу определить, куда осуществляется переход. С другой стороны, такой переход носит статический характер - его нельзя настраивать по ходу программы. Еще более серьезный недостаток прямых переходов заключается в том, что они не дают возможность перейти по известному абсолютному адресу, т.е. не позволяют обратиться ни к системным средствам, ни вообще к другим загруженным в память программам (например, резидентным). Действительно, программы операционной системы не имеют никаких меток, так как метка - это атрибут исходного текста программы, а программы операционной системы транслировались не нами и присутствуют в компьютере только в виде выполнимых модулей. А вот адреса каких-то характерных точек системных программ определить можно, хотя бы из векторов прерываний. Для обращения по абсолютным адресам надо воспользоваться командами косвенных переходов, которые, как и прямые, могут быть ближними и дальними.
Косвенный ближний (внутрисегментный) переход. В отличие от команд прямых переходов, команды косвенных переходов могут использовать различные способы адресации и, соответственно, иметь много разных вариантов. Общим для них яштястся то, что адрес перехода не указывается явным образом в виде метки, а содержится либо в ячейке памяти, либо в одном из регистров. Это позволяет при необходимости модифицировать адрес перехода, а также осущестштять переход по известному абсолютному адресу. Рассмотрим случай, когда адрес перехода хранится в ячейке сегмента данных. Если переход ближний, то ячейка с адресом состоит из одного слова и содержит только смещение к точке перехода.
code segment
…
jmp DS:go_addr ;Код FF 26 dddd
…
go: ; Точка перехода
…
code ends
data segment
…
go_addr dw go ;Адрес перехода (слово)
…
data ends
Точка перехода go может находиться в любом месте сегмента команд. В коде команды dddd обозначает относительный адрес слова go_addr в сегменте данных, содержащем эту ячейку.
В приведенном фрагменте адрес точки перехода в слове go_addr задан однозначно указанием имени метки go. Такой вариант косвенного перехода выполняет фактически те же функции, что и прямой (переход по единственному заданному заранее адресу), только несколько более запутанным образом. Достоинства косвенного перехода будут более наглядны, если представить, что ячейка go_addr поначалу пуста, а по ходу выполнения программы в нес, в зависимости от каких-либо условий, помещается адрес той или иной точки перехода:
mov go_addr, offset gol
mov go_addr, offset go2
mov go_addr, offset go3
Разумеется, приведенные выше команды должны выполняться не друг за другом, а альтернативно. В этом случае создается возможность перед выполнением перехода определить или даже вычислить адрес перехода, требуемый в данных условиях.
Ассемблер допускает различные формы описания косвенного перехода через ячейку сегмента данных:
jmp DS:go_addr
jmp word ptr go_addr
jmp go_addr
В первом варианте, использованном в приведенном выше фрагменте, указано, через какой сегментный регистр надлежит обращаться к ячейке go_addr, содержащей адрес перехода. Здесь допустима замена сегмента, если сегмент с ячейкой go_addr адресуется через другой сегментный регистр, например, ES или CS.
Во втором варианте подчеркивается, что переход осуществляется через ячейку размером в одно слово и, следовательно, является ближним. Ячейка go_addr могла быть объявлена с помощью директивы dd и содержать полный двухсловный адрес перехода, требуемый для реализации дальнего перехода. Однако ею можно воспользоваться и для ближнего перехода. Описатель word ptr перед именем ячейки с адресом перехода засташшет транслятор считать, что она имеет размер 1 слово (независимо от того, как она была объявлена), и что переход, следовательно, является ближним.
Наконец, возможен и самый простой, третий вариант, который совпадает по форме с прямым переходом, но, тем не менее, является косвенным, так как символическое обозначение go_addr является именем поля данных, а не программной меткой. В этом варианте предполагается, что сегмент, в котором находится ячейка go_addr, адресуется по умолчанию через регистр DS, хотя, как и во всех таких случаях, допустима замена сегмента. Тип перехода (ближний или дальний) определяется, исходя из размера ячейки go_addr. Однако этот вариант не всегда возможен. Для его правильной трансляции необходимо, чтобы транслятору к моменту обработки предложения
jmp go_addr
было уже известно, что собой представляет имя go_addr. Этого можно добиться двумя способами. Первый - расположить сегмент данных до сегмента команд, а не после, как в приведенном выше примере. Второй - заставить транслятор обрабатывать исходный текст программы не один раз, как он это делает по умолчанию, а несколько. Число проходов для транслятора TASM можно задать при его вызове с помощью ключа /m#, где # - требуемое число проходов. В нашем случае достаточно двух проходов.
В приведенных примерах адрес поля памяти с адресом точки перехода задавался непосредственно в коде команды косвенного перехода. Однако этот адрес можно задать и в одном из регистров общего назначения (ВХ, SI или DI). Для приведенного выше примера косвенного перехода в точку go, адрес которой находится в ячейке go_addr в сегменте данных, перс-ход с использованием косвенной регистровой адресации может выглядеть следующим образом:
mov BX, offset go_addr ;В ВХ смещение поля с адресом перехода
jmp [BX] ;Переход в точку gо
Особенно большие возможности предоставляет методика косвенного перехода с использованием базово-индексной адресации через пары регистров, например, [BX][SI] или [BX][DI]. Этот способ удобен в тех случаях, когда имеется ряд альтернативных точек перехода, выбор которых зависит от некоторых условий. В этом случае в сегменте данных создается не одно поле с адресом, а таблица адресов переходов. В базовый регистр ВХ загружается адрес этой таблицы, а в один из индексных регистров - определенный тем или иным способом индекс в этой таблице. Переход осуществляется в точку, соответствующую заданному индексу. Структура программы, использующий такую методику, выглядит следующим образом:
code segment
mov BX, off set go_tbl ;Загружаем в ВХ базовый адрес таблицы
mov SI, 4 ;Вычисленное каким-то
;образом смещение в таблице
jmp [BX] [SI] ;Если индекс =4, переход в точку goЗ
…
gol: ;1-я точка перехода
…
gо2 : ;2-я точка перехода
…
gоЗ: ;3-я точка перехода
…
code ends
data segment
go_tbl label word ;Таблица адресов переходов
gol_addr dw gol ;Адрес первой альтернативной
;точки перехода
go2_addr dw go2 ;Адрес второй альтернативной
;точки перехода
go3_addr dw доЗ ;Адрес третьей альтернативной
;точки перехода
data ends
Приведенный пример носит условный характер; в реальной программе индекс, помещаемый в регистр SI, должен вычисляться по результатам анализа некоторых условий.
Наконец, существует еще одна разновидность косвенного перехода, в котором не используется сегмент данных, а адрес перехода помещается непосредственно в один из регистров общего назначения. Часто такой переход относят к категории прямых, а не косвенных, однако это вопрос не столько принципа, сколько терминологии.
Применительно к обозначениям последнего примера такой переход будет выглядеть, например, следующим образом:
mov BX, off set gol jmp BX
Здесь, как и в предыдущих вариантах, имеется возможность вычисления адреса перехода, однако нельзя этот адрес индексировать.
Косвенный дальний (межсегментный) переход. Как и в случае ближнего перехода, переход осуществляется по адресу, который содержится в ячейке памяти, однако эта ячейка имеет размер 2 слова, и в ней содержится полный (сегмент плюс смещение) адрес точки перехода. Программа в этом случае должна включать по меньщей мере два сегмента команд. Структура программы с использованием косвенного дальнего перехода может выглядеть следующим образом:
codel segment
assume CS:codel,DS:data
…
jmp DS:go_addr ; Код FF 2E dddd
…
codel ends
code2 segment
assume CS:code2
…
go: ;Точка перехода в другом сегменте команд
…
code2 ends
data segment
…
go_addrdd go ;Двухсловный адрес точки перехода
…
data ends
Точка перехода go находится в другом сегменте команд этой двухсегментной программы. В коде команды dddd обозначает относительный адрес слова go_addr в сегменте данных. Ячейка go_addr объявляется директивой dd (define double, определить двойное слово) и содержит двухсловный адрес точки перехода; в первом слове содержится смещение go в сегменте команд codel, во втором слове сегментный адрес codel. Оба компонента адреса перехода могут быть вычислены и помещены в ячейку go_addr по ходу выполнения программы.
Как и в случае ближнего косвенного перехода, ассемблер допускает различные формы описания дальнего косвенного перехода через ячейку сегмента данных:
jmp DS:go_addr ;Возможна замена сегмента
jmp dword ptr go_addr ;Если поле go_addr объявлено
;операторами dw
jmp go_addr ;Характеристики ячейки должны
;быть известны
Для дальнего косвенного перехода, как и для ближнего, допустима адресация через регистр общего назначения, если в него поместить адрес поля с адресом перехода:
mov BX,offset go_addr
jmp [BX]
Возможно также использование базово-индексной адресации, если в сегменте данных имеется таблица с двухсловными адресами точек переходов.
Вызовы подпрограмм
Практически в любой программе, независимо от ее содержания, встречаются участки, которые требуется выполнять (возможно, с небольшими изменениями) несколько раз по ходу программы. Такие повторяющиеся участки целесообразно выделить из общей программы, оформить в виде подпрограмм и обращаться к ним каждый раз, когда в основной программе возникает необходимость их выполнения.
Подпрограмма, в зависимости от выполняемых ею функций, может требовать передачи из вызывающей программы определенных данных (называемых аргументами, или параметрами), возвращать в вызывающую программу результаты вычислений или обходиться и без того, и без другого.
Подпрограмма может быть оформлена в виде процедуры, и тогда имя этой процедуры будет служить точкой входа в подпрограмму:
drawline proc ;Подпрограмма-процедура
. . . ;Тело подпрограммы
ret ;Команда возврата в вызывающую программу
drawline endp
С таким же успехом можно обойтись без процедуры, просто пометив первую строку программы некоторой меткой:
drawline: ;Подпрограмма, начинающаяся с метки
. . . ;Тело подпрограммы
ret ;Команда возврата в вызывающую программу
. . . ;Продолжение основной программы или
;другие подпрограммы
В любом случае вызов подпрограммы осуществляется командой call. Подпрограмма должна завершаться командой ret, служащей для возврата управления в ту точку, откуда подпрограмма была вызвана.
Вопросы использования подпрограмм, передачи в них параметров и возвращения результата будут рассмотрены в следующей главе. Здесь мы остановимся только на таких принципиальных архитектурных вопросах, как механизм выполнения и возможности команд call и ret. При этом надо иметь в виду, что синтаксические особенности и закономерности использования команд call и jmp во многом совпадают, и значительная часть пояснений к командам перехода справедлива и для команд вызова.
Команда вызова подпрограммы call может использоваться в 4 разновидностях. Вызов может быть:
прямым ближним (в пределах текущего сегмента команд);
прямым дальним (в другой сегмент команд);
косвенным ближним (в пределах текущего сегмента команд через ячейку с адресом перехода);
косвенным дальним (в другой сегмент команд через ячейку с адресом
перехода).
Рассмотрим последовательно перечисленные варианты.
Прямой ближний вызов. Как и в случае прямого ближнего перехода, в команде прямого вызова в явной форме указывается адрес (смещение) точки входа в подпрограмму; в качестве этого адреса можно использовать как имя процедуры, так и имя метки, характеризующей точку входа в подпрограмму. В код команды, кроме кода операции E8h, входит смещение к вызываемой подпрограмме. В приведенном ниже примере подпрограмма оформлена в виде процедуры.
code segment
main proc ;Основная программа
…
call sub ;Код Е8 dddd
…
main endp
sub proc near ;Подпрограмма
…
ret ;Код СЗ
sub endp
code ends
Процедура-программа находится в том же сегменте команд, что и вызывающая программа. В коде команды dddd обозначает смещение в сегменте команд к точке входа в подпрограмму. При выполнении команды call процессор помещает адрес возврата (содержимое регистра IP) в стек выполняемой программы (рис. 2.16), после чего к текущему содержимому IP прибавляет dddd. В результате в IP оказывается адрес подпрограммы. Команда ret, которой заканчивается подпрограмма, выполняет обратную процедуру - извлекает из стека адрес возврата и заносит его в IP.

Рис. 2.16. Участие стека в механизме вызова ближней подпрограммы.
Участие стека в механизме вызова подпрограммы и возврата из нее является решающим. Поскольку в стеке хранится адрес возврата, подпрограмма, сама используя стек, например, для хранения промежуточных результатов, обязана к моменту выполнения команды ret вернуть стек в исходное состояние. Команда ret, естественно, никак не анализирует состояние или содержимое стека. Она просто снимает со стека верхнее слово, считая его адресом возврата, и загружает это слово в указатель команд IP. Если к моменту выполнения команды ret указатель стека окажется смещенным в ту или иную сторону, команда ret по-прежнему будет рассматривать верхнее слово стека, как адрес возврата, и передаст по нему управление, что неминуемо приведет к краху системы.
Прямой дальний вызов. Этот вызов позволяет обратиться к подпрограмме из другого сегмента. В код команды, кроме кода операции 9Ah, входит полный адрес (сегмент плюс смещение) вызываемой подпрограммы. Обычно в исходном тексте программы с помощью описателя far ptr указывается, что вызов является дальним, хотя, если транслятор настроен на трансляцию в два прохода, этот описатель не обязателен. Структура программного комплекса, содержащая дальний вызов подпрограммы, может выглядеть следующим образом:
codel segment
assume CS:codel
main proc ;Основная программа
call far ptr subr ; Код 9А dddd ssss
…
main endp
codel ends
code2 segment
assume CS:code2
subr proc far ;Объявляем подпрограмму дальней
…
ret ;Код СВ - дальний возврат
subr endp
code2 ends
Процедура-подпрограмма находится в другом сегменте команд той же программы. В коде команды dddd обозначает относительный адрес точки входа в подпрограмму в ее сегменте команд, a ssss - се сегментный адрес. При выполнении команды call процессор помещает в стек сначала сегментный адрес вызывающей программы, а затем относительный адрес возврата (рис. 2.17). Далее в сегментный регистр CS заносится 5555 (у нас это значение code2), а в IP - dddd (у нас это значение subr). Поскольку процедура-подпрограмма атрибутом far объявлена дальней, команда ret имеет код, отличный от кода аналогичной команды ближней процедуры и выполняется по-другому: из стека извлекаются два верхних слова и переносятся в IP и CS, чем и осуществляется возврат в вызывающую программу, находящуюся в другом сегменте команд. В языке ассемблера существует и явное мнемоническое обозначение команды дальнего возврата - retf.

Рис. 2.17. Участие стека в механизме вызова дальней подпрограммы.
Косвенный ближний вызов. Адрес подпрограммы содержится либо в ячейке памяти, либо в регистре. Это позволяет, как и в случае косвенного ближнего перехода, модифицировать адрес вызова, а также осуществлять вызов не с помощью метки, а по известному абсолютному адресу. Структура программы с косвенным вызовом подпрограммы может выглядеть следующим образом:
code segment
main proc ;Основная программа
…
call DS:subadr ;Код FF 16 dddd
main endp
subr proc near ;Подпрограмма
…
ret ;Код СЗ
subr endp
code ends
data segment
…
subadr dw subr ;Яейка с адресом подпрограммы
data ends
Процедура-программа с атрибутом near находится в том же сегменте, что и вызывающая программа, а ее относительный адрес в ячейке subadr в сегменте данных. В коде команды dddd обозначает относительный адрес слова subadr в сегменте данных. Второй байт кода команды (16h в данном примере) зависит от способа адресации. Косвенный вызов позволяет использовать разнообразные способы адресации подпрограммы:
call BX ; В ВХ адрес подпрограммы
call[BX] ; В ВХ адрес ячейки с адресом подпрограммы
call[BX][SI] ;В ВХ адрес таблицы адресов подпрограмм,
;в SI индекс в этой таблице.
tbl[SI] ;tbl - адрес таблицы адресов подпрограмм,
;в SI индекс в этой таблице
Косвенный дальний вызов. Отличается от косвенного ближнего вызова лишь тем, что подпрограмма находится в другом сегменте, а в ячейке памяти содержится полный адрес подпрограммы, включающий сегмент и смещение.
codel segment
main proc ;Основная программа
call dword ptr subadr ;Код FF IE dddd
…
main endp
codel ends
code2 segment
subr proc far ;Подпрограмма
…
ret ;Код СВ
subr endp
code2 ends
data segment
…
subadr dd subr ;Двухсловная ячейка с
;адресом подпрограммы
data ends
Процедура-подпрограмма с атрибутом far находится в другом сегменте команд той же программы, а ее полный двухсловный адрес - в ячейке subadr в сегменте данных. Второй байт кода команды (IE в данном примере) зависит от способа адресации. Косвенный дальний вызов, как и косвенный ближний, позволяет использовать различные способы адресации.
Макросредства ассемблера
Современные ассемблеры содержат в себе так называемые макросредства и по этой причине называются иногда макроассемблерами. Общая идея макросредств заключается в том, что включением в исходный текст программы предложений специального языка макросредств (макроязыка) мы в какой-то степени управляем процессом трансляции программы. Макроязык позволяет выполнять или не выполнять трансляцию отдельных участков программы в зависимости от некоторого нами же определяемого условия (условная трансляция); осуществлять размножение участка исходного текста программы, в том числе, с модификацией каждого повторения (блоки повторения); включать в программу написанные отдельно фрагменты с настройкой их текста в соответствии с заданными параметрами (макрокоманды). Объекты, создаваемые с помощью директив макроязыка, обычно называют макросами. Иногда, правда, термин макрос относят только к одному конкретному виду макросредств, именно, к макрокоманде. Использование макросов упрощает составление исходного текста программы и иногда делает этот текст более наглядным, хотя в отдельных случаях, как, например, в случае директив условной трансляции, наоборот, может привести к существенному усложнению исходного текста.
Как и во всяком языке программирования, в языке макросредств имеется много разного рода тонкостей, но в прикладном программировании зачастую используются лишь базовые возможности этого языка. Поэтому мы ограничимся здесь рассмотрением основных макросредств ассемблера.
Блоки повторения
Блоки повторения заставляют транслятор повторить заданный блок исходного текста указанное число раз. Повторяемый блок может состоять из директив описания данных (и тогда он включается в состав сегмента данных) или из команд процессора (и тогда он описывается в программном сегменте). Например, следующий фрагмент сегмента данных позволяет образовать массив, состоящий из кодов ASCII прописных русских букв:
sym='A' ;Начальное значение временной переменной
symbols: ;Имя массива для ссылок на него
rept 32 ;Повторять столько раз
db sym ;Повторяемая директива
sym=sym+l ;Изменение переменной
endm ;Конец блока повторения
Как видно из приведенного фрагмента, блок повторения начинается с директивы ассемблера rept (от repetition, повторение), а заканчивается директивой endm (end macro, конец макроса). Реально в сегменте данных выделяется 32 байт, заполненных числами от 81h до 9Fh, которые предполагается рассматривать, как последовательность русских букв. Того же результата можно было достигнуть с помощью следующего предложения:
symbols db "А", "Б", "В", "Г", и т.д. до буквы Я
или проще, хотя и менее наглядно:
symbols db 128,129,130,131, и т.д. до числа 159.
Макрос повторения несколько сокращает время, требуемое для описания в тексте программы требуемого массива, хотя, возможно, снижает наглядность этого описания.
При подключении к компьютеру измерительного или управляющего оборудования иногда возникает необходимость замедлить работу процессора при обращении к портам этого оборудования. Замедление осуществляется включением в текст программы одной или, если требуется, нескольких команд безусловного перехода на следующее предложение:
in AL,300h ;Первое обращение к оборудованию
jmp a ;Задержка на время
a: jmp b ;выполнения
b: jmp с ;трех команд jmp
c: in AL,301h ;Следующее обращение к оборудованию
Для того, чтобы не создавать много ненужных, в сущности, меток, такого рода предложения часто записывают следующим образом:
in AL, 300h ;Первое обращение к оборудованию
jmp $+2 ;Задержка на время
jmp $+2 ;выполнения
jmp $+2 ;трех команд jmp
in AL,301h ;Следующее обращение к оборудованию
Здесь используется обозначение счетчика текущего адреса S. При трансляции любой команды в счетчике текущего адреса содержится адрес этой команды (смещение ее первого байта). Команда короткого перехода занимает 2 байт, поэтом}' команда jmp $+2 осуществляет переход на команду, идущую следом.
Часто в подобных случаях ограничиваются одной командой jmp, которая создает необходимую задержку в доли микросекунды. В тех случаях, однако, когда устройство сопряжения с оборудованием работает заметно медленнее процессора, приходится включать между командами обращения к портам 5-6 команд jmp. Такой фрагмент можно оформить в виде блока повторения:
rept 6 jmp $+2 endm
Это, пожатуй, проще, чем писать 6 команд jmp.
Макросы повторения имеют несколько разновидностей, которые мы не будем здесь рассматривать.
Макрокоманды
Программы, написанные на языке ассемблера, часто содержат повторяющиеся участки текста с одинаковой структурой. Такой участок текста можно оформить в виде макроопределения, характеризующегося произвольным именем и необязательным списком формальных аргументов. После того, как такое определение сделано, появление в программе строки, содержащей имя макроопределения и список фактических аргументов (все это вместе называют макрокомандой), приводит к генерации всего требуемого текста, называемого макрорасширением. Варьируя фактические аргументы, можно, сохраняя неизменной структуру макрорасширения, изменить отдельные его элементы.
Макроопределение должно начинаться строкой с именем макроопределения и директивой macro, в поле аргументов которой указывается список формальных аргументов. Заканчивается макроопределение директивой endm.
Пусть в программе требуется неоднократно сохранять в стеке содержимое трех регистров, но в каждом конкретном случае номера регистров и их порядок отличаются. Оформим эти действия в виде макроопределения:
psh macroa,b,c
push a
push b
push с
endm
Появление в исходном тексте программы строки
psh АХ, ВХ, СХ
приведет к генерации следующего фрагмента текста:
push AX push BX push CX
Если же в исходном тексте имеется строка
psh DX, ES, ВР
то
соответствующее макрорасширение будет иметь вид:
push DX
push ES
push BP
В качестве фактических аргументов могут выступать любые обозначения ассемблера, допустимые для данной команды. В частности, макровызов
psh mem, [BX], ES: [17h]
приведет к следующему макрорасширению:
push mem
push [BX]
push ES : [17h]
Если какие-то строки макроопределения должны быть помечены (например, с целью организации циклов), то обозначения меток следует объявить локальными с помощью оператора local. В этом случае ассемблер, генерируя макрорасширения, будет создавать собственные обозначения меток, не повторяющиеся при повторных вызовах одной и той же макрокоманды:
delay macro
local point
mov CX,200
point: loop point
endm
Макрос delay создает задержку фиксированной длительности. Если в текст программы включить две макрокоманды delay
…
delay
…
delay
то их макрорасширения, подставленные в текст программы, будут выглядеть следующим образом:
…
mov CX, 20000
??0000: loop ??0000
…
mov CX, 20000
??0000: loop ??0000
При повторных подстановках макроопределения транслятор заменяет обозначение метки point на различающиеся обозначения ??0000, ??0001 и т.д., обеспечивая тем самым правильное выполнение команд циклов и переходов.
Макрокоманды схожи с подпрограммами в том отношении, что в обоих случаях мы описываем некоторый программный фрагмент один раз, а обращаемся к нему многократно, возможно, с передачей различных параметров. Однако эти вычислительные средства различаются как по способу использования, так и по своим возможностям.
Подпрограммы позволяют сократить объем выполнимого файла за счет описания повторяющихся участков программы лишь однажды. При каждом вызове подпрограммы командой call происходит переход на один и тот же фрагмент программы, содержащий подпрограмму, а после выполнения подпрограммы - возврат назад в точку вызова. Текст подпрограммы полностью определяется на этапе ее написания, и изменения в ходе выполнения подпрограммы возможны только за счет передачи ей тех или иных конкретных значений.
Механизм использования макроса иной. Каждая макрокоманда, встретившаяся транслятору в тексте программы, заменяется им на полный текст макроопределения. Если макрокоманда содержит параметры, то в процессе этой замены происходит подстановка параметров в текст макроопределения. Образованное таким образом макрорасширение составляет часть текста программы, неотличимо от остальных предложений программы и не нуждается в каких-либо вызовах. В силу этих обстоятельств макрокоманды оказываются несколько эффективнее подпрограмм по скорости выполнения, особенно, если учесть время, требуемое для подготовки параметров перед вызовом подпрограммы (например, проталкивание их в стек). Вряд ли стоит, однако, проводить такое сравнение. Подпрограммы и макрокоманды имеют различные области применения.
Подпрограммы служат для сокращения объема программы, повышения ее наглядности и упрощения перестройки алгоритма выполнения всего программного комплекса путем изменения состава и порядка вызываемых подпрограмм. При этом активное использование подпрограмм может уменьшить размер всей программы в десятки раз.
Смысл использования макрокоманд совсем иной. Макрокоманды позволяют упростить процесс написания программы и, можно сказать, являются средством автоматизации программирования. При этом язык макрокоманд предоставляет большие возможности по изменению текста макрорасширения в зависимости от указываемых в макрокоманде параметров. Проиллюстрируем эти возможности на простом примере макрокоманды вывода на экран символа. Такой макрокомандой можно пользоваться в процессе отладки сложных программ, чтобы получать информацию о содержимом любых ячеек памяти. Пример оформлен в виде законченной программы, которая носит чисто демонстрационный характер.
;Пример 2-1. Использование макрокоманды
sym macroc ;Имя и формальный аргумент
push AX ;Сохраним используемые
push DX ;в макроопределении регистры
mov АН, 02h ;Функция DOS вывода символа
mov DL,c ;Заберем символ
int 21h ;Вызов DOS
pop DX ;Восстановим
pop AX ;регистры
endm ;Конец макроопределения
code segment
assume cs:code
main proc
sym 'w' ;Символ указан непосредственно
sym ES : 0 ;Вывод первого байта PSP
sym CS:msg ;Вывод первой буквы из msg
lea BX,msg-t-l ;Адрес второй буквы из msg
sym [BX] ;Вывод второй буквы
mov AX, 40h ;Настроим DS
mov DS,AX ;на начало памяти
sym DS:49h ;Вывод номера видеорежима
mov AX,4C00h ;Завершение программы
int 21h
main endp
msg db 'OK'
code ends
Тексты макроопределений обычно размещаются в самом начале программы, что дает возможность вызывать макрокоманды из любых точек программы. Содержательная часть макроса sym состоит в вызове функции 02h DOS, которая выводит на экран символ из регистра DL. Поскольку макрос использует регистры АХ и DX, они в начале макроса сохраняются в стеке, а перед его завершением восстанавливаются. В качестве параметра макрокоманды можно использовать любое обозначение ассемблера, которое может интерпретироваться, как адрес символа.
Сама программа умышленно построена несколько нестандартным образом. В ней имеется единственный сегмент с текстом программы, в конце которого помещена строка данных (слово 'ОК'). Такое расположение данных допустимо, однако для обращения к ним необходимо использовать замену сегмента (как это сделано в третьей строке программы), так как программный сегмент адресуется через регистр CS. Сегмент стека в программе отсутствует, что не очень хорошо, но для небольших программ допустимо. Фактически под стек будет использован самый низ сегмента команд, начиная с адреса FFFEh. Поскольку наша программа имеет размер, существенно меньше 64К, такое расположение стека не приведет ни к каким неприятностям (при большом размере программы стек мог бы начать затирать нижние строки программы).
В программе проиллюстрировано использование в качестве фактического аргумента макрокоманды различных конструкций языка: непосредственного обозначения символа (что, наверное, лишено смысла), прямого обращения к различным участкам памяти по абсолютным адресам через регистры ES и DS, адресации с использованием символического обозначения поля данных. На рис. 2.18 приведен вывод программы.

Рис. 2.18. Вывод программы 2.1.
Как уже отмечалось, при загрузке программы в память в регистры DS и ES заносится сегментный адрес префикса программы, поэтому адресация через ES позволяет прочитать содержимое PSP. Префикс содержит, главным образом, данные, необходимые системе для обслуживания текущей программы, но, кроме того, и несколько команд. В частности, префикс начинается с команды CD 20h, которая уже давно не используется, но в префиксе присутствует ради обеспечения совместимости со старыми версиями DOS. Первый байт этой команды, если его рассматривать, как код символа, соответствует элементу двойной горизонтальной рамки (длинный знак равенства).
Занеся в регистр DS число 40h, мы настроили его на начало области данных BIOS, которая начинается с абсолютного адреса 400h, занимает 256 байт и содержит разнообразные данные, используемые BIOS в процессе обслуживания аппаратуры компьютера. Так, например, по адресу 0 от начала этой области хранится базовый адрес первого последовательного порта; по адресу 8 - адрес первого параллельного порта, а по адресу 491i - код текущего видеорежима. При работе в DOS видеоадаптер обычно настраивается на режим 3 (80x25 символов, 16 цветов). Будучи выведен на экран, код 3 образует изображение червонного туза.
В тех случаях, когда макрокоманды составляются для конкретной программы, они включаются в текст программы так, как это было сделано в примере 2.1. Однако часто программист оформляет в виде макрокоманд стандартные процедуры общего назначения, например, программную задержку или вывод на экран строки текста. В этом случае тексты макроопределений целесообразно поместить в макробиблиотеку.
Макробиблиотека представляет собой файл с текстами макроопределений. Макроопределения записываются в этот файл точно в таком же виде, как и в текст программы. Ниже приведен текст файла макробиблиотеки с произвольным именем MYMACRO.MAC, содержащей две макрокоманды.
;Макрокоманда endpr завершения программы
endpr macro ;Макрокоманда без параметров
mov AX,4C00h
int 2 In
endm ;Конец макрокоманды
;Макрокоманда delay настраиваемой программной задержки
delay macro time ;Параметр - число шагов
locallabell,Iabel2 ;Локальные метки
push CX ;Сохраним внешний счетчик
mov CX,time ;Получим фактический параметр
Iabel2 : push CX ;Сохраним его в стеке
mov CX, 0 ;Пусть будет 64К шагов
labell: loop lanell ;Внутренний цикл
pop CX ;Извлечем внешний счетчик
loop Iabel2 ;Внешний цикл
pop CX ;Восстановим CX программы
endm ;Конец макрокоманды
Для того чтобы транслятору были доступны макрокоманды из файла MYMACRO.MAC, его следует на этапе трансляции подсоединить к исходному тексту программы директивой ассемблера include:
include my macro, mac
Все макрокоманды, включенные в этот файл, можно использовать в любом месте программы.
Директивы условной трансляции
Директивы условной трансляции (условного ассемблирования) позволяют иметь в исходном тексте программы различные варианты отдельных фрагментов программы, и путем задания определенных условий управлять процессом трансляции. Таким образом можно, например, включать или исключать из текста программы служебные, отладочные фрагменты или настраивать программу для выполнения на заданном процессоре.
Пусть, например, в процессе отладки сложной программы мы используем подпрограмму regs вывода на экран содержимого всех регистров процессора. Включая в разные места программы вызов этой подпрограммы, мы имеем возможность контролировать ход ее выполнения, в том числе и такие тонкие моменты, как, например, расположение программы в памяти или интенсивность использование стека. Для управления процессом трансляции предусмотрим константу debug (отладка), ненулевое значение которой будет требовать отладочного варианта трансляции, а нулевое - рабочего. Начало программы, а также участки с вызовом отладочной подпрограммы будут выглядеть следующим образом:
;debug=l ;Удалите символ ';'для отладочной трансляции
;debug=0 ;Удалите ';' для рабочей трансляции
... ;Текст программы
if debug ;Транслировать только если debug=l
call regs;Вызов отладочной подпрограммы
endif ;Конец блока условной трансляции
… ;Продолжение программы
if debug ;Следующее включение отладочного блока
call regs
endif
... ;Продолжение программы
Разумеется, можно отлаживать программу в отладочном варианте, а затем удалить все вызовы вспомогательной подпрограммы regs вручную и получить рабочий вариант, однако на практике обычно (или даже всегда) оказывается, что после эксплуатации программы в течение некоторого времени в ней обнаруживаются незамеченные ранее ошибки, что приводит к необходимости снова вставлять в нее отладочные строки. Часто эту процедуру приходится повторять многократно. Использование в программе директив условной трансляции сокращают процедуру преобразования программы из отладочного варианта в рабочий или наоборот до операции стирания одного символа ";" в начале программы и устраняют вероятность случайного внесения в программу новых ошибок в процессе удаления или вставки отладочных строк.
Рассмотрим еще один пример применения директив условной трансляции. Как уже отмечалось, современные процессоры предоставляют программисту значительное количество дополнительных команд, которые можно использовать в программах реального режима, но только, разумеется, если компьютер оснащен соответствующим процессором. Нетрудно составить универсальную программу', которую можно выполнять как на современных процессорах (в более эффективном режиме), так и на более старых (с некоторой потерей эффективности), если включить в нее директивы условной трансляции этих дополнительных команд. К таким командам, в частности, относятся команды сохранения в стеке всех регистров общего назначения pusha и восстановления всех регистров рора. Приведем пример условной трансляции этих команд, в котором используется конструкция макроязыка if... else... endif:
i386=l
if i386
.386
endif
code segment use16
assume CS:code
main proc
…
if i386
push ;Сохранение всех регистров одной командой
else
push AX
push CX
push DX
push BX
push BP
push SI
push DI
endif
. . . ;Использование регистров после
;сохранения их значений
if 1386
рора ;Восстановление всех регистров одной командой
else
pop DI
pop SI
pop BP
pop BX
pop DX
pop CX
pop AX
endif
Если в начале программы имеется объявление i386=1, то, во-первых, в программу будет включена директива .386, позволяющая использовать в программе дополнительные команды, а во-вторых, в последующих условных блоках будут транслироваться те их участки, которые содержат команды процессора 80386. Если же объявление i386=1 изъять, то в условных блоках будут транслироваться эквивалентные по существу, но менее эффективные последовательности команд МП 86.