Обработка цепочек элементов
Глава 4. Обработка цепочек элементов

Обработка цепочек элементов
Обработка цепочек элементов
Конструктор знает, что он достиг совершенства
не тогда, когда нечего больше добавить,
а тогда, когда нечего больше убрать.
Антуан де Сент-Экзюпери
Материал этой главы является дополнением к уроку 11 «Цепочечные команды» учебника. Из этого урока следуют выводы о том, что, во-первых, цепочечные команды являются мощным инструментом обработки последовательностей элементов размером 1/2/4 байт и, во-вторых, это единственное средство микропроцессора для обработки данных по схеме память-память. В процессе разработки программ для учебника и этой книги мы достаточно часто использовали команды микропроцессора этой группы. Но цепочечные команды — это примитивы, и, как любые примитивы, они являются лишь основой для построения более сложных алгоритмов обработки цепочек элементов. Особенно это чувствуется при разработке программ для задач обработки текстов, и в частности задачи поиска. Для решения этой проблемы существует ряд классических алгоритмов, оптимизирующих этот процесс. Ниже будет приведено несколько программ, демонстрирующих алгоритмы поиска данных в строках символов, то есть цепочках элементов размером 1 байт. Так как все они построены на основе стандартных байтовых цепочечных команд микропроцессора, то при необходимости обработки последовательностей элементов большей размерности (2 и 4 байта) их доработка не составит вам особого труда.
Организацию поиска одиночного символа в программе на ассемблере мы рассматривать не будем, так как это делается самими цепочечными командами без привлечения посторонней алгоритмической поддержки. Информацию об этом можно получить из учебника.
Более подробно мы рассмотрим организацию поиска текстовой подстроки в строке символов, превышающей размер искомой подстроки. При всей кажущейся простоте этого вида поиска его реализация в программах на языке ассемблера сопряжена с рядом проблем.
Введем некоторые обозначения:
Р — строка-аргумент поиска, размерность строки Р - М байт, j — индекс символа в строке Р, 0 <j < М-1;
S- строка, в которой ведется поиск строки Р, размерность строки S - N байт, i — индекс символа в строке S, 0 < i < N-1.
Все алгоритмы поиска в текстовой строке можно разбить на два класса: прямые и учитывающие особенности объектов поиска. Последний класс алгоритмов предполагает предварительный анализ искомой подстроки и формирование на его основе некоторой информации, управляющей процессом поиска.
Поиск с предварительным анализом искомой подстроки
Поиск с предварительным анализом искомой подстроки
Против незнания есть только одно средство — знание.
Истинное же знание может быть достигнуто
только через личное совершенствование.
Л. Н. Толстой
Основу материала этого раздела составляет алгоритм КМП-поиска. Имя «КМП» является выборкой первых букв фамилий его создателей: Д. Кнута, Д. Мориса
и В. Пратта. В основе алгоритма КМП-поиска лежит идея о том, что в процессе просмотра строки S с целью поиска вхождения в нее образца Р становится известной информация о просмотренной части. Работа алгоритма производится в два этапа.
1. Анализируется строка-образец Р. По результатам анализа заполняется вспомогательный массив смещений D.
2. Производится поиск в строке S с использованием строки-образца Р и массива смещений D.
Ниже приведена программа, реализующая алгоритм КМП-поиска.
//рrg4_73_КМР - программа на псевдоязыке поиска строки Р в строке S
//по алгоритму КМП-поиска. Длина S фиксирована. ..<. ¦ ¦¦ ¦¦
// Вход: S и Р - массивы символов размером N и М байт (M=<N)
II Выход: сообщение о количестве вхождений строки Р в строку S.
ПЕРЕМЕННЫЕ .
INT_BYTE s[n]://0=<i<N-l
INT_BYTE p[m]://0-<j<M-l .
INT_BYTE d[ml://массив смещений
INT_BYTE k=-l: i=0: j-0 //индексы
НАЧ_ПРОГ .
//этап 1: формирование массива смещений d
' И j:-0; k:-l:'d[0]
ПОКА ДЕЛАТЬ
НАЧ_БЛОК 1 .
nOKA~"((k>=0)M(p[j]<>p[k])) k:-d[k]
j:=j+l: k:-k+l :
ЕСЛИ p[j]-p[k] TO d[j]:-d[k] .
ИНАЧЕ d[j]:-k .
кон_блок_1 .
//этап 2: поиск
i:-0: j:-0: k:=0
ПОКА ((j<M)M(i<N)) ДЕЛАТЬ
НАЧ_БЛОК_1 ' '" '"'
ПОКА ((j>=O)H(s[i]<>p[j])) j:-dtj]
j:-j+l: i:=i+l
КОН_БЛОК_1
ЕСЛИ j=M TO зывод сообщения об удаче поиска
ИНАЧЕ вывод сообщения о неудаче поиска КОН ПРОГ
jmpm3
ml: :ЕСЛИ j=M TO вывод сообщения об удаче поиска :вывод сообщения о результатах поиска
cmp si ,len_p
jneexit_f :ИНАЧЕ вывод сообщения о неудаче поиска
inc count
cmp di ,len_s
jgeexit_f
xor si ,si
jmp m34
exit_f:add count.30h :вывод сообщения mes на экран
Подробно, хотя и не очень удачно, алгоритм КМП-поиска описан у Вирта [4]. Этот алгоритм достаточно сложен для понимания, хотя в конечном итоге его идея проста. Центральное место в алгоритме КМП-поиска играет вспомогательный массив D. Поясним его назначение. Массив D содержит значения, которые нужно добавить к текущему значению j в позиции первого несовпадения символов в строке S и подстроке Р (Рисунок 4.1).

Рис 4.1. Пример КМП-поиска
Из обсуждения выше можно сделать два вывода — один приятный, другой не очень. Во-первых, явное достоинство этого метода в том, что исключены возвраты
:задаем массив S
s db "fgcabceabcaab"
Len_S=$-s :N=Len_S
db Count db 0 ;счетчик вхождений Р в S
Db " раз(а)$"
d db 255 dup (0) вспомогательный массив ¦' ¦ k db 0 .,.,.,'
.code
:этап 1 - заполнение массива D значением М - размером образца для поиска
mov ex.255 :размер кодовой таблицы ASCII
moval.lenjj :ДЛЯ j=0 ДО 255 ДЕЛАТЬ
lea di .d rep stosb :d[j]:=M
:цикл просмотра образца и замещение некоторых элементов d значениями смещений :(см. пояснение за текстом программы)
xor si .si ; j:=0 '
cycll: :ДЛЯ j>0 ДО М-2 ДЕЛАТЬ ..>;
empsi ,1еп_р-1
jgee_cycll
mov al ,p[si]
movdi.ax
movbl.len_p
decbl
subbx.si
movd[di],bl :d[p[j]]:-MrJ-l:!
inc si ¦, -.r
e_cycll: ://этап 2: поиск
movdi,len_p
cycl 2:,; ПОВТОРИТЬ - цикл пока (j>-0)WW(I<n) . movsi.len_p :j:=M . , ;¦
movbx.di :k:=I . '.
cycl3: :цикл пока (j>-O)MJlH(p[j]~p[k])
decbx :k:-k-l . ' '¦' '
dec si :j:-j-l cmp si.0 jl m2
mov al.p[si] cmps[bx].al jnem2 jmpcycl3 m2: ;i:-i+d[s[i-: push di dec di
mov al,s[di] mov di ,ax moval .dfdi] popdi
add di .ax cmp s i, 0 jl ml cmp di .len_s
jg exi t_f
jmp cycl2 ml: ;вывод сообщения о результатах поиска
inc count
jmpcycl2 exit_f:add count.30h
lea dx.mes
mov ah.09h
int 21h exit:
Идея алгоритма БМ-поиска в том, что сравнению подвергаются не первые, а последние символы образца Р и очередного фрагмента строки S. Если они не равны, то сдвиг в строке S осуществляется сразу на всю длину образца. Если последние символы равны, то сравнению подвергаются предпоследние символы, и т. д. При несовпадении очередных символов величина сдвига извлекается из таблицы D, которая, таким образом, выполняет ключевую роль в этом алгоритме. Заполнение таблицы происходит на основе конкретной строки-образца Р следующим образом. Размер таблицы определяется размером алфавита, то есть количеством кодов символов, которые могут появляться в тексте. В нашем случае мы отвели под таблицу D память длиной, равной длине кодовой таблицы ASCII. Таким образом, строки S и Р могут содержать любые символы. Первоначально все байты кодовой таблицы заполняются значением, равным длине строки-образца для поиска Р. Далее последовательно извлекаются символы строки-образца Р начиная с первого. Для каждого символа определяется позиция его самого правого вхождения в строку-образец Р. Это значение и заносится в таблицу D на место, соответствующее этому символу. Подробнее получить представление о заполнении таблицы можно по фрагменту программы на псевдоязыке:
//этап 1: формирование массива d .ДЛЯ j- О ДО 255 ДЕЛАТЬ НАЧ_БЛ0К_1 d[j]:-M К0Н_БЛ0К_1
ДЛЯ j=0 ДО М-2 ДЕЛАТЬ НАЧ_БЛОК_1
d[p[j]]:-M-j-l КОН_БЛОК_1
Так, для строки abcdabce процесс и результаты формирования таблицы D показаны на Рисунок 4.2.
Куда в двух последних программах пристроить цепочечные команды? К сожалению, некуда. Честно говоря, когда автор писал текст этих программ, он настолько увлекся, что напрочь забыл как о них, так и о цели настоящего раздела — показать особенности использования этих команд при организации поиска информации. А когда вспомнил, то сделал вывод, что пристроить их вроде бы и некуда. А вы как думаете? Окончательный вывод об эффективности можно сделать по результатам работы профайлера.
Развитие этой темы лежит в плоскости обсуждения проблемы обработки файлов, к которой мы когда-нибудь вернемся.
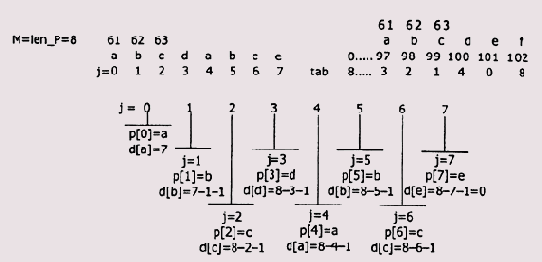
Рисунок 4.2. Формирование массива D в программе БМ-поиска
Прямой поиск в текстовой строке
Прямой поиск в текстовой строке
«Корень зла есть незнание истины», — сказал Будда.
Из этого же корня вырастает дерево заблуждения
со своими тысячными плодами страдания.
Цель поиска некоторой строки Р в строке большего размера S — определить первый индекс элемента в строке S, начиная с которого все символы S совпадают с символами строки Р. Для этого алгоритм поиска последовательно просматривает символы строки S, проводя одновременное сравнение ее очередного символа с первым символом строки Р. После возникновения такого совпадения алгоритм производит последовательное сравнение соответствующих элементов строк S и Р до возникновения одного из следующих условий:
в процессе поиска соответствия достигнут конец строки Р — это означает,
что строка Р совпадает с некоторой подстрокой строки S;
достигнут конец строки S при незавершенном или неначатом просмотре строки Р — это означает, что строка Р не соответствует ни одна из подстрок S.
Одна из главных проблем, которую приходится решать при написании программы обработки символьной строки, — определение конца строки S. Здесь возможны два варианта:
статический — размер строки фиксирован некоторым значением N;
динамический (характерен для обработки массивов символьных строк) — длина строки определяется значением, являющимся либо первым элементом очередной строки, либо концевым (служебным) символом, значение которого заранее определено и не может совпадать ни с одним символом строки.
Начнем обсуждение прямого способа поиска с программы поиска в строке с фиксированной длиной. Для экономии места ограничим число вхождений Р в S рдним.
;prg4_67_f.asm - поиск строки Р в строке S, Длина S фиксирована.
;Вход: S и Р - массивы символов размером N и М байт (М=<N.
:Выход: сообщение о количестве вхождений строки Р в строку S.
'.data"
:задаем массив S
s db "Ax. какой был яркий день! Лодка, солнце, блеск и тень, и везде цвела сирень."
Len_S=$-s
Db "$" mes db "Вхождений строки - "
:задаем массив Р - аргумент поиска
р db "ень"
1_еп_Р=$-р
db " - " Count (Jb 0."$" :счетчик вхождений Р a S
.code
eld
movcx.len_s
lea di ,s
moval ,p ;P[0]->al next_search:
lea si,p
incsi ;на следующий символ repne scasb
jcxz exit push ex
mov cx.len_p-l repe empsb
jz eq_substr :строка p <> подстроке в s
mov bx.len_p-l
sub bx.cx pop ex
subcx.bx ;учли пройденное при сравнении empsb
jmp next_search eq_substr:
; далее можно выйти, если поиск однократный, но мы упорные, поэтому продолжаем... рорех
sub сх.1еп_р-1 ;учли пройденное при сравнении empsb
inc count
jmp next_search exit: add count,30h :вывод сообщения mes на экран
Из программы видно, что когда размер строки фиксирован, то проблема конца строки решается просто. Но чаще приходится иметь дело с задачами, выполняющими поиск подстроки в строке, длина которой заранее не известна. Это характерно, в частности, для приложений обработки файлов. Но и с файлами не так все просто. Для текстовых ASCII-файлов особых проблем нет — в них строки заканчиваются символами Odh, Oah. Сложнее дело обстоит с обработкой двоичных файлов, где с равной степенью вероятности могут встретиться любые символы кодовой таблицы. В подобных случаях проблему локализации места в файле, где осуществляется поиск, нужно решать исходя из постановки конкретной задачи. Несмотря на это, сами приемы поиска не сильно отличаются от рассмотренных в этом разделе.
В случае когда поиск осуществляется в строке или в массиве строк в памяти, длина которых заранее не известна, то для обозначения их окончаний нужно ввести некоторый служебный символ. Например, в языке Паскаль существует понятие строки ASCII-Z, представляющей собой обычную символьную строку с завершающим нулевым символом. По этому символу и определяется конец строки. Подобные служебные символы можно использовать и для обработки строк
¦ в памяти. Другая возможность задания границы строки — введение в структуру строки специального байта, обычно первого, содержащего длину этой строки.
Следующая программа демонстрирует возможную организацию поиска в текстовом файле. Для этого содержимое файла читается в динамически выделяемую область памяти. После небольшой модернизации данную программу можно рассматривать как основу для других программ поиска в строках памяти, ограниченных некоторым служебным символом, как это обсуждалось выше. Программа производит поиск слова «шалтай» в строках файла. На экран выводится номер строки, в которой встретилось это слово, и количество повторений этого слова в файле. В такой постановке задачи возникает проблема — необходимо отслеживать наступление одного из двух событий: обнаружение первого символа образца или обнаружение первого из пары символов OdOah, обозначающих конец строки. Вариант использования цепочечных команд из предыдущей программы не подходит, так как сканировать строку можно на предмет наличия только одного символа. Поэтому данную задачу можно реализовать двумя способами. Первый способ заключается в последовательном чтении и проверке каждого символа строки на предмет удовлетворения их одному из обозначенных выше событий. При втором способе каждая строка файла сканируется два раза. На первом проходе определяется размер очередной строки, а затем эта строка сканируется второй раз на предмет наличия в ней искомой подстроки. Достоинство второго способа состоит в том, что его можно реализовать только использованием цепочечных команд. Какой из способов будет работать быстрее, можно определить с помощью профайлера. Мы выберем второй способ по двум причинам: во-первых, в этом разделе нас интересуют варианты использования цепочечных команд; во-вторых, в одной программе мы продемонстрируем приемы работы со строкой, размер которой определяется динамически двумя способами: со служебным символом в конце (им будет Odh) и извлекаемым из байта в начале строки. В нашей программе байт со значением длины очередной строки будет эмулироваться первым проходом.
start proc near :точка входа в программу:
;для размещения файла используем кучу, выделяемую процессу по умолчанию (1 Мбайт)
;HANDLE GetProcessHeap (VOID);
call GetProcessHeap
inov Hand_Head.eax сохраняем дескриптор ;читаем файл в динамически выделяемую область памяти ;открываем файл
:HANDLE CreateFiIeCLPCTSTR ipFileName.DWORD dwDesiredAccess.DWORD ;dwShareMode.LPSECURITY_ATTRIBUTES 1pSecuri tyAttributes.DWORD
:dwCreationDisposition.DWORD :dwFlagsAndAttributes.HANDLE hTemplateFi1e):
call CreateFileA
cmp eax.Offffffffh
je exit :если неуспех
mov hFile.eax :дескриптор файла определим размер файла :DWORD GetFi1eSize(HANDLE hFile.LPDWORD ipFileSizeHigh);
call GetFileSize
cmp eax.O
jz exit :если неуспех
mov FileSize.eax :сохраним размер файла :запрашиваем блок памяти из кучи:
:LPVOID HeapAlloc(HANDLE hHeap. DWORD dwFlags, DWORD dwBytes): ;.........
call HeapAlloc
mov buf_start,eax :адрес блока с текстом программы из общей кучи процесса :читаем файл
:BOOL ReadFile(HANDLE hFile.LPVOID ipBuffer.DWORD nNumberOfBytesToRead. ;LPDWORD lpNumberOfBytesRead.LPOVERLAPPED lpOverlapped):
:.........
call ReadFile
cmp eax.O
jz exit :если неуспех push ds pop es
eld
mov ecx.FileSize
movedi.buf_start :адрес буфера с текстом файла в edi cycll: push ecx push edi
mov ebx.ecx
moval.Odh :0dh ->al repne scasb
jcxz e_exit
jmp $+7 e_exit: jmp exit pop edi
sub ebx.ecx
xchg ebx.ecx
mov al.p :P[0]->al next_search: repne scasb
jcxz end_str:достигнут конец строки проверяем возможное совпадение
push ecx lea esi.p
mov ecx.len_p-l repe empsb
jz eq_substr :строка р <> подстроке в s
mov edx.len_p-l
sub edx.ecx
sub ecx.edx :учли пройденное при сравнении empsb
jmp next_search end_str: incedi
xchg ebx.ecx преобразуем в символьное представление счетчик вхождений count
:вывод на экран строки mes call WriteConsoleA
mov count.0 обнуляем счетчик вхождений в строку pop ecx :1 - восстанавливаем
sub ecx.len_p-учли пройденное при сравнении empsb
inc count
jmp next_search
exit: pop ecx
;выход из программы - задержим ввод до нажатия любой клавиши
Этой программой мы проиллюстрировали оба варианта поиска с динамическим определением размера строки.
Алгоритмы, реализованные в этих программах, можно использовать для организации поиска в строке S небольшой длины, так как попытки повысить эффективность приведут к излишним накладным расходам. Для строки S большой размерности (потоковые данные для приложений мультимедиа) прямые алгоритмы поиска могут быть неэффективными. Положение можно исправить рассмотренными ниже алгоритмами поиска с предварительным анализом искомой подстроки.