Арифметические действия над упакованными BCD-числами
Как уже отмечалось выше, упакованные BCD-числа можно только складывать и вычитать. Для выполнения других действий над ними их нужно дополнительно преобразовывать либо в неупакованный формат, либо в двоичное представление. Из-за того, что упакованные BCD-числа представляют не слишком большой интерес, мы их рассмотрим кратко.
Арифметические операции над целыми двоичными числами
В данном разделе мы рассмотрим особенности каждого из четырех основных арифметических действий для двоичных чисел со знаком и без знака:
Арифметические операции над двоично-десятичными числами
В данном разделе мы рассмотрим особенности каждого из четырех основных арифметических действия для упакованных и неупакованных двоично-десятичных чисел:
У вас справедливо может возникнуть вопрос: а зачем нужны BCD-числа? Ответ может быть следующим: BCD-числа нужны в деловых приложениях, то есть там, где числа должны быть большими и точными. Как мы уже убедились на примере двоичных чисел, операции с такими числами довольно проблематичны для языка ассемблера. К недостаткам использования двоичных чисел можно отнести следующие:
значения величин в формате слова и двойного слова имеют ограниченный диапазон. Если программа предназначена для работы в области финансов, то ограничение суммы в рублях величиной 65 536 (для слова) или даже 4 294 967 296 (для двойного слова) будет существенно сужать сферу ее применения (да еще в наших экономических условиях — тут уж никакая деноминация не поможет);
наличие ошибок округления. Представляете себе программу, работающую где-нибудь в банке, которая не учитывает величину остатка при действиях с целыми двоичными числами и оперирует при этом миллиардами? Не хотелось бы быть автором такой программы. Применение чисел с плавающей точкой не спасет — там существует та же проблема округления;
представление большого объема результатов в символьном виде (ASCII-коде). Деловые программы не просто выполняют вычисления; одной из целей их использования является оперативная выдача информации пользователю. Для этого, естественно, информация должна быть представлена в символьном виде. Перевод чисел из двоичного кода в ASCII- код, как мы уже видели, требует определенных вычислительных затрат. Число с плавающей точкой еще труднее перевести в символьный вид. А вот если посмотреть на шестнадцатеричное представление неупакованной десятичной цифры (в начале нашего занятия) и на соответствующий ей символ в таблице ASCII, то видно что они отличаются на величину 30h. Таким образом, преобразование в символьный вид и обратно получается намного проще и быстрее.
Наверняка, вы уже убедились в важности овладения хотя бы основами действий с десятичными числами. Далее рассмотрим особенности выполнения основных арифметических операций с десятичными числами. Для предупреждения возможных вопросов отметим сразу тот факт, что отдельных команд сложения, вычитания, умножения и деления BCD-чисел нет. Сделано это по вполне понятным причинам: размерность таких чисел может быть сколь угодно большой. Складывать и вычитать можно двоично-десятичные числа как в упакованном формате, так и в неупакованном, а вот делить и умножать можно только неупакованные BCD-числа. Почему это так, будет видно из дальнейшего обсуждения.
Целые двоичные числа
Целое двоичное число с фиксированной точкой — это число, закодированное в двоичной системе счисления.
Размерность целого двоичного числа может составлять 8, 16 или 32 бит. Знак двоичного числа определяется тем, как интерпретируется старший бит в представлении числа. Это 7-й, 15-й или 31-й биты для чисел соответствующей размерности (см. Типы данных ). При этом интересно то, что среди арифметических команд есть всего две команды, которые действительно учитывают этот старший разряд как знаковый, — это команды целочисленного умножения и деления imul и idiv. В остальных случаях ответственность за действия со знаковыми числами и, соответственно, со знаковым разрядом ложится на программиста. К этому вопросу мы вернемся чуть позже. Диапазон значений двоичного числа зависит от его размера и трактовки старшего бита либо как старшего значащего бита числа, либо как бита знака числа (табл. 1).
Таблица 1. Диапазон значений двоичных чисел
| Размерность поля | Целое без знака | Целое со знаком |
| байт | 0...255 | –128...+127 |
| слово | 0...65 535 | –32 768...+32 767 |
| двойное слово | 0...4 294 967 295 | –2 147 483 648...+2 147 483 647 |
Как описать числа с фиксированной точкой в программе?
Это делается с использованием директив описания данных. К примеру, последовательность описаний двоичных чисел из сегмента данных листинга 1 (помните о принципе “младший байт по младшему адресу”) будет выглядеть в памяти так, как показано на рис. 2.
| Листинг 1. Числа с фиксированной точкой ;prg_8_1.asm masm model small stack 256 .data ;сегмент данных per_1 db 23 per_2 dw 9856 per_3 dd 9875645 per_4 dw 29857 .code ;сегмент кода main: ;точка входа в программу mov ax,@data ;связываем регистр dx с сегментом mov ds,ax ;данных через регистр ax exit: ;посмотрите в отладчике дамп сегмента данных mov ax,4c00h ;стандартный выход int 21h end main ;конец программы |

Рис. 2. Дамп памяти для сегмента данных листинга 1
Деление чисел без знака
Для деления чисел без знака предназначена команда
div делитель
Делитель может находиться в памяти или в регистре и иметь размер 8, 16 или 32 бит. Местонахождение делимого фиксировано и так же, как в команде умножения, зависит от размера операндов. Результатом команды деления являются значения частного и остатка.
Варианты местоположения и размеров операндов операции деления показаны в табл. 3.
Таблица 3. Расположение операндов и результата при делении
| Делимое | Делитель | Частное | Остаток |
| 16 бит в регистре ax |
Байт регистр или ячейка памяти |
Байт в регистре al |
Байт в регистре ah |
| 32 бит dx — старшая часть ax — младшая часть |
Слово 16 бит регистр или ячейка памяти |
Слово 16 бит в регистре ax |
Слово 16 бит в регистре dx |
| 64 бит edx — старшая часть eax — младшая часть |
Двойное слово 32 бит регистр или ячейка памяти |
Двойное слово 32 бит в регистре eax |
Двойное слово 32 бит в регистре edx |
После выполнения команды деления содержимое флагов неопределенно, но возможно возникновение прерывания с номером 0, называемого “деление на ноль”. Этот вид прерывания относится к так называемым исключениям. Эта разновидность прерываний возникает внутри микропроцессора из-за некоторых аномалий во время вычислительного процесса. Прерывание 0, “деление на ноль”, при выполнении команды div может возникнуть по одной из следующих причин:
делитель равен нулю;
частное не входит в отведенную под него разрядную сетку, что может случиться в следующих случаях:
при делении делимого величиной в слово на делитель величиной в байт, причем значение делимого в более чем 256 раз больше значения делителя;
при делении делимого величиной в двойное слово на делитель величиной в слово, причем значение делимого в более чем 65 536 раз больше значения делителя;
при делении делимого величиной в учетверенное слово на делитель величиной в двойное слово, причем значение делимого в более чем 4 294 967 296 раз больше значения делителя.
К примеру, выполним деление значения в области del на значение в области delt (листинг 6).
| Листинг 6. Деление чисел <1> ;prg_8.6.asm <2> masm <3> model small <4> stack 256 <5> .data <6> del_b label byte <7> deldw 29876 <8> delt db 45 <9> .code ;сегмент кода <10> main: ;точка входа в программу <11> ... <12> xor ax,ax <13> ;последующие две команды можно заменить одной mov ax,del <14> mov ah,del_b ;старший байт делимого в ah <15> mov al,del_b+1 ;младший байт делимого в al <16> div delt ;в al — частное, в ah — остаток <17> ... <18> endmain ;конец программы |
Деление чисел со знаком
Для деления чисел со знаком предназначена команда
idiv делитель
Для этой команды справедливы все рассмотренные положения, касающиеся команд и чисел со знаком. Отметим лишь особенности возникновения исключения 0, “деление на ноль”, в случае чисел со знаком. Оно возникает при выполнении команды idiv по одной из следующих причин:
делитель равен нулю;
частное не входит в отведенную для него разрядную сетку.
Последнее в свою очередь может произойти:
при делении делимого величиной в слово со знаком на делитель величиной в байт со знаком, причем значение делимого в более чем 128 раз больше значения делителя (таким образом, частное не должно находиться вне диапазона от –128 до +127);
при делении делимого величиной в двойное слово со знаком на делитель величиной в слово со знаком, причем значение делимого в более чем 32 768 раз больше значения делителя (таким образом, частное не должно находиться вне диапазона от –32 768 до +32 768);
при делении делимого величиной в учетверенное слово со знаком на делитель величиной в двойное слово со знаком, причем значение делимого в более чем 2 147 483 648 раз больше значения делителя (таким образом, частное не должно находиться вне диапазона от –2 147 483 648 до +2 147 483 647).
Деление неупакованных BCD-чисел
Процесс выполнения операции деления двух неупакованных BCD-чисел несколько отличается от других, рассмотренных ранее, операций с ними. Здесь также требуются действия по коррекции, но они должны выполняться до основной операции, выполняющей непосредственно деление одного BCD-числа на другое BCD-число. Предварительно в регистре ax нужно получить две неупакованные BCD-цифры делимого. Это делает программист удобным для него способом. Далее нужно выдать команду aad:
aad (ASCII Adjust for Division) — коррекция деления для представления в символьном виде.
Команда не имеет операндов и преобразует двузначное неупакованное BCD-число в регистре ax в двоичное число. Это двоичное число впоследствии будет играть роль делимого в операции деления. Кроме преобразования, команда aad помещает полученное двоичное число в регистр al. Делимое, естественно, будет двоичным числом из диапазона 0...99.
Алгоритм, по которому команда aad осуществляет это преобразование, состоит в следующем:
умножить старшую цифру исходного BCD-числа в ax (содержимое ah) на 10;
выполнить сложение ah + al, результат которого (двоичное число) занести в al;
обнулить содержимое ah.
Далее программисту нужно выдать обычную команду деления div для выполнения деления содержимого ax на одну BCD-цифру, находящуюся в байтовом регистре или байтовой ячейке памяти.
Деление неупакованных BCD-чисел иллюстрируется листингом 11.
| Листинг 11. Деление неупакованных BCD-чисел <1> ;prg_8_11.asm <2> ... <3> .data ;сегмент данных <4> b db 1,7 ;неупакованное BCD-число 71 <5> c db 4 ; <6> ch db 2 dup (0) <7> .code ;сегмент кода <8> main: ;точка входа в программу <9> ... <10> mov al,b <11> aad ;коррекция перед делением <12> div c ;в al BCD-частное, в ah BCD-остаток <13> ... <14> exit: |
Аналогично aam, команде aad можно найти и другое применение — использовать ее для перевода неупакованных BCD-чисел из диапазона 0...99 в их двоичный эквивалент.
Для деления чисел большей разрядности, так же как и в случае умножения, нужно реализовывать свой алгоритм, например “в столбик”, либо найти более оптимальный путь.
Десятичные числа
Десятичные числа — специальный вид представления числовой информации, в основу которого положен принцип кодирования каждой десятичной цифры числа группой из четырех бит. При этом каждый байт числа содержит одну или две десятичные цифры в так называемом двоично-десятичном коде (BCD — Binary-Coded Decimal). Микропроцессор хранит BCD-числа в двух форматах (рис. 3):
упакованном формате — в этом формате каждый байт содержит две десятичные цифры. Десятичная цифра представляет собой двоичное значение в диапазоне от 0 до 9 размером 4 бита. При этом код старшей цифры числа занимает старшие 4 бита. Следовательно, диапазон представления десятичного упакованного числа в одном байте составляет от 00 до 99;
неупакованном формате — в этом формате каждый байт содержит одну десятичную цифру в четырех младших битах. Старшие четыре бита имеют нулевое значение. Это так называемая зона. Следовательно, диапазон представления десятичного неупакованного числа в одном байте составляет от 0 до 9.

Рис. 3. Представление BCD-чисел
Как описать двоично-десятичные числа в программе?
Для этого можно использовать только две директивы описания и инициализации данных — db и dt. Возможность применения только этих директив для описания BCD-чисел обусловлена тем, что к таким числам также применим принцип “младший байт по младшему адресу”, что, как мы увидим далее, очень удобно для их обработки. И вообще, при использовании такого типа данных как BCD-числа, порядок описания этих чисел в программе и алгоритм их обработки — это дело вкуса и личных пристрастий программиста. Это станет ясно после того, как мы ниже рассмотрим основы работы с BCD-числами. К примеру, приведенная в сегменте данных листинга 2 последовательность описаний BCD-чисел будет выглядеть в памяти так, как показано на рис. 4.
| Листинг 2. BCD-числа ;prg_8_2.asm masm model small stack 256 .data ;сегмент данных per_1 db 2,3,4,6,8,2 ;неупакованное BCD-число 286432 per_3 dt 9875645 ;упакованное BCD-число 9875645 .code ;сегмент кода main: ;точка входа в программу mov ax,@data ;связываем регистр dx с сегментом mov ds,ax ;данных через регистр ax exit: ;посмотрите в отладчике дамп сегмента данных mov ax,4c00h ;стандартный выход int 21h end main ;конец программы |
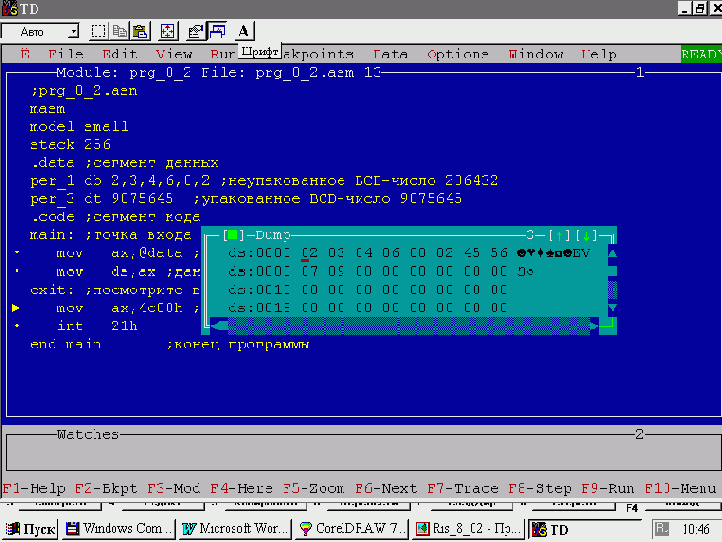
Рис. 4. Дамп памяти для сегмента данных листинга 2
После столь подробного обсуждения объектов, с которыми работают арифметические операции, можно приступить к рассмотрению средств их обработки на уровне системы команд микропроцессора.
Другие полезные команды
xadd назначение,источник — обмен местами и сложение.
Команда позволяет выполнить последовательно два действия:
обменять значения назначение и источник;
поместить на место операнда назначение сумму:
назначение = назначение + источник.
neg операнд — отрицание с дополнением до двух.
Команда выполняет инвертирование значения операнд. Физически команда выполняет одно действие:
операнд = 0 – операнд, то есть вычитает операнд из нуля.
Команду neg операнд можно применять:
для смены знака;
для выполнения вычитания из константы.
Дело в том, что команды sub и sbb не позволяют вычесть что-либо из константы, так как константа не может служить операндом-приемником в этих операциях. Поэтому данную операцию можно выполнить с помощью двух команд:
| neg ax ;смена знака (ax) ... add ax,340 ;фактически вычитание: (ax)=340-(ax) |
Команды преобразования типов
Что делать, если размеры операндов, участвующих в арифметических операциях, разные? Например, предположим, что в операции сложения один операнд является словом, а другой занимает двойное слово. Выше сказано, что в операции сложения должны участвовать операнды одного формата. Если числа без знака, то выход найти просто. В этом случае можно на базе исходного операнда сформировать новый (формата двойного слова), старшие разряды которого просто заполнить нулями. Сложнее ситуация для чисел со знаком: как динамически, в ходе выполнения программы, учесть знак операнда? Для решения подобных проблем в системе команд микропроцессора есть так называемые команды преобразования типа. Эти команды расширяют байты в слова, слова — в двойные слова и двойные слова — в учетверенные слова (64-разрядные значения). Команды преобразования типа особенно полезны при преобразовании целых со знаком, так как они автоматически заполняют старшие биты вновь формируемого операнда значениями знакового бита старого объекта. Эта операция приводит к целым значениям того же знака и той же величины, что и исходная, но уже в более длинном формате. Подобное преобразование называется операцией распространения знака.
Существуют два вида команд преобразования типа:
Команды без операндов — эти команды работают с фиксированными регистрами:
cbw (Convert Byte to Word) — команда преобразования байта (в регистре al) в слово (в регистре ax) путем распространения значения старшего бита al на все биты регистра ah;
cwd (Convert Word to Double) — команда преобразования слова (в регистре ax) в двойное слово (в регистрах dx:ax) путем распространения значения старшего бита ax на все биты регистра dx;
cwde (Convert Word to Double) — команда преобразования слова (в регистре ax) в двойное слово (в регистре eax) путем распространения значения старшего бита ax на все биты старшей половины регистра eax;
cdq (Convert Double Word to Quarter Word) — команда преобразования двойного слова (в регистре eax) в учетверенное слово (в регистрах edx:eax) путем распространения значения старшего бита eax на все биты регистра edx.
Команды movsx и movzx, относящиеся к командам обработки строк (см. урок 11). Эти команды обладают полезным свойством в контексте нашей проблемы:
movsx операнд_1,операнд_2 — переслать с распространением знака. Расширяет 8 или 16-разрядное значение операнд_2, которое может быть регистром или операндом в памяти, до 16 или 32-разрядного значения в одном из регистров, используя значение знакового бита для заполнения старших позиций операнд_1. Данную команду удобно использовать для подготовки операндов со знаками к выполнению арифметических действий;
movzx операнд_1,операнд_2 — переслать с расширением нулем. Расширяет 8 или 16-разрядное значение операнд_2 до 16 или 32-разрядного с очисткой (заполнением) нулями старших позиций операнд_2. Данную команду удобно использовать для подготовки операндов без знака к выполнению арифметических действий.
К примеру, вычислим значение y = (a + b)/c, где a, b, c — байтовые знаковые переменные (листинг 7).
|
Листинг 7. Вычисление простого выражения <1> ;prg_8_9.asm <2> masm <3> model small <4> stack 256 <5> .data <6> a db ? <7> b db ? <8> c db ? <9> y dw 0 <10> .code <11> main: ;точка входа в программу <12> ... <13> xor ax,ax <14> mov al,a <15> cbw <16> movsx bx,b <17> add ax,bx <18> idiv c ;в al — частное, в ah — остаток <19> exit: <20> mov ax,4c00h ;стандартный выход <21> int 21h <22> end main ;конец программы |
Обзор группы арифметических команд и данных
Целочисленное вычислительное устройство поддерживает чуть больше десятка арифметических команд.
На рис. 1 приведена классификация команд этой группы.

Рис. 1. Классификация арифметических команд
Группа арифметических целочисленных команд работает с двумя типами чисел:
целыми двоичными числами. Числа могут иметь знаковый разряд или не иметь такового, то есть быть числами со знаком или без знака;
целыми десятичными числами.
Рассмотрим машинные форматы, в которых хранятся эти типы данных.
и правильностью результата: переносов нет,
30566 = 01110111 01100110 + 00687 = 00000010 10101111 = 31253 = 01111010 00010101
Следим за переносами из 14-го и 15-го разрядов и правильностью результата: переносов нет, результат правильный.
го разряда переноса нет. Результат
30566 = 01110111 01100110 + 30566 = 01110111 01100110 = 61132 = 11101110 11001100
Произошел перенос из 14-го разряда; из 15- го разряда переноса нет. Результат неправильный, так как имеется переполнение — значение числа получилось больше, чем то, которое может иметь 16-битное число со знаком (+32 767).
го разряда нет переноса. Результат
-30566 = 10001000 10011010 + -04875 = 11101100 11110101 = -35441 = 01110101 10001111
Произошел перенос из 15-го разряда, из 14- го разряда нет переноса. Результат неправильный, так как вместо отрицательного числа получилось положительное (в старшем бите находится 0).
Таким образом, мы исследовали все
-4875 = 11101100 11110101 + -4875 = 11101100 11110101 = -9750 = 11011001 11101010
Есть переносы из 14 и 15-го разрядов. Результат правильный.
Таким образом, мы исследовали все случаи и выяснили, что ситуация переполнения (установка флага of в 1) происходит при переносе:
из 14-го разряда (для положительных чисел со знаком);
из 15-го разряда (для отрицательных чисел).
И наоборот, переполнения не происходит (то есть флаг of сбрасывается в 0), если есть перенос из обоих разрядов или перенос отсутствует в обоих разрядах.
Итак, переполнение регистрируется с помощью флага переполнения of. Дополнительно к флагу of при переносе из старшего разряда устанавливается в 1 и флаг переноса cf. Так как микропроцессор не знает о существовании чисел со знаком и без знака, то вся ответственность за правильность действий с получившимися числами ложится на программиста. Проанализировать флаги cf и of можно командами условного перехода jc\jnc и jo\jno соответственно.
Что же касается команд сложения чисел со знаком, то они те же, что и для чисел без знака.
Для того чтобы произвести вычитание,
05 = 00000000 00000101 -10 = 00000000 00001010 Для того чтобы произвести вычитание, произведем воображаемый заем из старшего разряда: 100000000 00000101 - 00000000 00001010 = 11111111 11111011
Тем самым по сути выполняется действие
(65 536 + 5) — 10 = 65 531,
0 здесь как бы эквивалентен числу 65 536. Результат, конечно, неверен, но микропроцессор считает, что все нормально, хотя факт заема единицы он фиксирует установкой флага переноса cf. Но посмотрите еще раз внимательно на результат операции вычитания. Это же –5 в дополнительном коде! Проведем эксперимент: представим разность в виде суммы 5 + (–10).
то есть мы получили тот
5 = 00000000 00000101 + (-10)= 11111111 11110110 = 1111111111111011
то есть мы получили тот же результат, что и в предыдущем примере.
Таким образом, после команды вычитания чисел без знака нужно анализировать состояние флага cf. Если он установлен в 1, то это говорит о том, что произошел заем из старшего разряда и результат получился в дополнительном коде.
Аналогично командам сложения, группа команд вычитания состоит из минимально возможного набора. Эти команды выполняют вычитание по алгоритмам, которые мы сейчас рассматриваем, а учет особых ситуаций должен производиться самим программистом. К командам вычитания относятся следующие:
dec операнд — операция декремента, то есть уменьшения значения операнда на 1;
sub операнд_1,операнд_2 — команда вычитания; ее принцип действия:
операнд_1 = операнд_1 – операнд_2
sbb операнд_1,операнд_2 — команда вычитания с учетом заема (флага cf ):
операнд_1 = операнд_1 – операнд_2 – значение_cf
Как видите, среди команд вычитания есть команда sbb, учитывающая флаг переноса cf. Эта команда подобна adc, но теперь уже флаг cf выполняет роль индикатора заема 1 из старшего разряда при вычитании чисел.
Рассмотрим пример (листинг 4) программной обработки ситуации, разобранной в примере 6.
|
Листинг 4. Проверка при вычитании чисел без знака <1> ;prg_8_4.asm <2> masm <3> model small <4> stack 256 <5> .data <6> .code ;сегмент кода <7> main: ;точка входа в программу <8> ... <9> xor ax,ax <10> mov al,5 <11> sub al,10 <12> jnc m1 ;нет переноса? <13> neg al ;в al модуль результата <14> m1: ... <15> exit: <16> mov ax,4c00h ;стандартный выход <17> int 21h <18> end main ;конец программы |
В этом примере в строке 11 выполняется вычитание. С указанными для этой команды вычитания исходными данными результат получается в дополнительном коде (отрицательный). Для того чтобы преобразовать результат к нормальному виду (получить его модуль), применяется команда neg, с помощью которой получается дополнение операнда. В нашем случае мы получили дополнение дополнения или модуль отрицательного результата. А тот факт, что это на самом деле число отрицательное, отражен в состоянии флага cf. Дальше все зависит от алгоритма обработки. Исследуйте программу в отладчике.
Судя по знаковому разряду, результат
Вычитание чисел со знаком 1
45 = 0010 1101 - -127 = 1000 0001 = -44 = 1010 1100
Судя по знаковому разряду, результат получился отрицательный, что, в свою очередь, говорит о том, что число нужно рассматривать как дополнение, равное –44. Правильный результат должен быть равен 172. Здесь мы, как и в случае знакового сложения, встретились с переполнением мантиссы, когда значащий разряд числа изменил знаковый разряд операнда. Отследить такую ситуацию можно по содержимому флага переполнения of. Его установка в 1 говорит о том, что результат вышел за диапазон представления знаковых чисел (то есть изменился старший бит) для операнда данного размера, и программист должен предусмотреть действия по корректировке результата.
Другой пример разности рассматривается в примере 7, но выполним мы ее способом сложения.
Здесь все нормально, флаг переполнения
Вычитание чисел со знаком 2
-45 — 45 = -45 + (-45)= -90. -45 = 1101 0011 + -45 = 1101 0011 = -90 = 1010 0110
Здесь все нормально, флаг переполнения of сброшен в 0, а 1 в знаковом разряде говорит о том, что значение результата — число в дополнительном коде.
Результат сложения не больше
Результат сложения не больше 9
6 = 0000 0110 + 3 = 0000 0011 = 9 = 0000 1001
Переноса из младшей тетрады в старшую нет. Результат правильный.
То есть мы получили уже
Результат сложения больше 9
06 = 0000 0110 + 07 = 0000 0111 = 13 = 0000 1101
То есть мы получили уже не BCD-число. Результат неправильный. Правильный результат в неупакованном BCD-формате должен быть таким:
0000 0001 0000 0011 в двоичном представлении (или 13 в десятичном).
Проанализировав данную проблему при сложении BCD-чисел (и подобные проблемы при выполнении других арифметических действий) и возможные пути ее решения, разработчики системы команд микропроцессора решили не вводить специальные команды для работы с BCD-числами, а ввести несколько корректировочных команд.
Назначение этих команд — в корректировке результата работы обычных арифметических команд для случаев когда операнды в них являются BCD-числами.
В случае вычитания в примере 10 видно, что полученный результат нужно корректировать. Для коррекции операции сложения двух однозначных неупакованных BCD-чисел в системе команд микропроцессора существует специальная команда
aaa (ASCII Adjust for Addition) — коррекция результата сложения для представления в символьном виде.
Эта команда не имеет операндов. Она работает неявно только с регистром al и анализирует значение его младшей тетрады:
если это значение меньше 9, то флаг cf сбрасывается в 0 и осуществляется переход к следующей команде;
если это значение больше 9, то выполняются следующие действия:
к содержимому младшей тетрады al (но не к содержимому всего регистра!) прибавляется 6, тем самым значение десятичного результата корректируется в правильную сторону;
флаг cf устанавливается в 1, тем самым фиксируется перенос в старший разряд, для того чтобы его можно было учесть в последующих действиях.
Так, в примере 10, предполагая, что значение суммы 0000 1101 находится в al, после команды aaa в регистре будет 1101 + 0110= 0011, то есть двоичное 0000 0011 или десятичное 3, а флаг cf установится в 1, то есть перенос запомнился в микропроцессоре. Далее программисту нужно будет использовать команду сложения adc, которая учтет перенос из предыдущего разряда. Приведем пример программы сложения двух неупакованных BCD-чисел.
|
Листинг 8. Сложение неупакованных BCD-чисел <1> ;prg_8_8.asm <2> ... <3> .data <4> lenequ 2 ;разрядность числа <5> b db 1,7 ;неупакованное число 71 <6> c db 4,5 ;неупакованное число 54 <7> sum db 3 dup (0) <8> .code <9> main: ;точка входа в программу <10> ... <11> xor bx,bx <12> mov cx,len <13> m1: <14> mov al,b[bx] <15> adс al,c[bx] <16> aaa <17> mov sum[bx],al <18> inc bx <19> loop m1 <20> adc sum[bx],0 <21> ... <22> exit: |
В листинге 8 есть несколько интересных моментов, над которыми есть смысл поразмыслить. Начнем с описания BCD-чисел. Из строк 5 и 6 видно, что порядок их ввода обратен нормальному, то есть цифры младших разрядов расположены по меньшему адресу. Но это вполне логично по нескольким причинам:
во-первых, такой порядок удовлетворяет общему принципу представления данных для микропроцессоров Intel;
во-вторых, это очень удобно для поразрядной обработки неупакованных BCD-чисел, так как каждое из них занимает один байт.
Хотя, как уже было отмечено, программист сам волен выбирать способ описания BCD-чисел в сегменте данных. Строки 14–15 содержат команды, которые складывают цифры в очередных разрядах BCD-чисел, при этом учитывается возможный перенос из младшего разряда. Команда aaa в строке 16 корректирует результат сложения, формируя в al BCD-цифру и, при необходимости, устанавливая в 1 флаг cf. Строка 20 учитывает возможность переноса при сложении цифр из самых старших разрядов чисел. Результат сложения формируется в поле sum, описанном в строке 7.
Как видим, заема из старшей
Результат вычитания не больше 9
6 = 0000 0110 - 3 = 0000 0011 = 3 = 0000 0011
Как видим, заема из старшей тетрады нет. Результат верный и корректировки не требует.
Вычитание проводится по правилам двоичной
Результат вычитания больше 9
6 = 0000 0110 - 7 = 0000 0111 = -1 = 1111 1111
Вычитание проводится по правилам двоичной арифметики. Поэтому результат не является BCD-числом.
Правильный результат в неупакованном BCD-формате должен быть 9 (0000 1001 в двоичной системе счисления). При этом предполагается заем из старшего разряда, как при обычной команде вычитания, то есть в случае с BCD числами фактически должно быть выполнено вычитание 16 – 7. Таким образом видно, что, как и в случае сложения, результат вычитания нужно корректировать. Для этого существует специальная команда:
aas (ASCII Adjust for Substraction) — коррекция результата вычитания для представления в символьном виде.
Команда aas также не имеет операндов и работает с регистром al, анализируя его младшую тетраду следующим образом:
если ее значение меньше 9, то флаг cf сбрасывается в 0 и управление передается следующей команде;
если значение тетрады в al больше 9, то команда aas выполняет следующие действия:
из содержимого младшей тетрады регистра al (заметьте — не из содержимого всего регистра) вычитает 6;
обнуляет старшую тетраду регистра al;
устанавливает флаг cf в 1, тем самым фиксируя воображаемый заем из старшего разряда.
Понятно, что команда aas применяется вместе с основными командами вычитания sub и sbb. При этом команду sub есть смысл использовать только один раз, при вычитании самых младших цифр операндов, далее должна применяться команда sbb, которая будет учитывать возможный заем из старшего разряда. В листинге 9 мы обходимся одной командой sbb, которая в цикле производит поразрядное вычитание двух BCD-чисел.
|
Листинг 9. Вычитание неупакованных BCD-чисел <1> ;prg_8_9.asm <2> masm <3> model small <4> stack 256 <5> .data ;сегмент данных <6> b db 1,7 ;неупакованное число 71 <7> c db 4,5 ;неупакованное число 54 <8> subs db 2 dup (0) <9> .code <10> main: ;точка входа в программу <11> mov ax,@data ;связываем регистр dx с сегментом <12> mov ds,ax ;данных через регистр ax <13> xor ax,ax ;очищаем ax <14> lenequ 2 ;разрядность чисел <15> xor bx,bx <16> mov cx,len ;загрузка в cx счетчика цикла <17> m1: <18> mov al,b[bx] <19> sbb al,c[bx] <20> aas <21> mov subs[bx],al <22> inc bx <23> loop m1 <24> jc m2 ;анализ флага заема <25> jmp exit <26> m2:... <27> exit: <28> mov ax,4c00h ;стандартный выход <29> int 21h <30> end main ;конец программы |
Данная программа не требует особых пояснений, когда уменьшаемое больше вычитаемого. Поэтому обратите внимание на строку 24. С ее помощью мы предусматриваем случай, когда после вычитания старших цифр чисел был зафиксирован факт заема. Это говорит о том, что вычитаемое было больше уменьшаемого, в результате чего разность будет неправильной. Эту ситуацию нужно как-то обработать. С этой целью в строке 24 командой jc анализируется флаг cf. По результату этого анализа мы уходим на ветку программы, обозначенную меткой m2, где и будут выполняться некоторые действия.
в двоичном виде результат равен
Сложение упакованных BCD-чисел
67 = 0110 0111 + 75 = 0111 0101 = 142 = 1101 1100 = 220
Как видим, в двоичном виде результат равен 1101 1100 (или 220 в десятичном представлении), что неверно. Это происходит по той причине, что микропроцессор не подозревает о существовании BCD-чисел и складывает их по правилам сложения двоичных чисел. На самом деле, результат в двоично-десятичном виде должен быть равен 0001 0100 0010 (или 142 в десятичном представлении).
Видно, что как и для неупакованных BCD-чисел, для упакованных BCD-чисел существует потребность как-то корректировать результаты арифметических операций.
Микропроцессор предоставляет для этого команду daa:
daa (Decimal Adjust for Addition) — коррекция результата сложения для представления в десятичном виде.
Команда daa преобразует содержимое регистра al в две упакованные десятичные цифры по алгоритму, приведенному в описании команды .
Получившаяся в результате сложения единица (если результат сложения больше 99) запоминается в флаге cf, тем самым учитывается перенос в старший разряд.
Проиллюстрируем сказанное на примере сложения двух двузначных BCD-чисел в упакованном формате (листинг 12).
|
Листинг 12. Сложение упакованных BCD-чисел <1> ;prg_8_12.asm <2> ... <3> .data ;сегмент данных <4> b db 17h ;упакованное число 17h <5> c db 45h ;упакованное число 45 <6> sumdb 2 dup (0) <7> .code ;сегмент кода <8> main: ;точка входа в программу <9> ... <10> mov al,b <11> add al,c <12> daa <13> jnc $+4 ;переход через команду, если результат <= 99 <14> mov sum+1,ah ;учет переноса при сложении (результат > 99) <15> mov sum,al ;младшие упакованные цифры результата <16> exit: |
В приведенном примере все достаточно прозрачно, единственное, на что следует обратить внимание, — это описание упакованных BCD-чисел и порядок формирования результата. Результат формируется в соответствии с основным принципом работы микропроцессоров Intel: младший байт по младшему адресу.
Так как микропроцессор выполняет вычитание
Вычитание упакованных BCD-чисел
Выполним вычитание 67-75. Так как микропроцессор выполняет вычитание способом сложения, то и мы последуем этому: 67 = 0110 0111 + -75 = 1011 0101 = -8 = 0001 1100 = 28 ???
Как видим, результат равен 28 в десятичной системе счисления, что является абсурдом. В двоично-десятичном коде результат должен быть равен 0000 1000 (или 8 в десятичной системе счисления).
При программировании вычитания упакованных BCD-чисел программист, как и при вычитании неупакованных BCD-чисел, должен сам осуществлять контроль за знаком. Это делается с помощью флага cf, который фиксирует заем из старших разрядов.
Само вычитание BCD-чисел осуществляется простой командой вычитания sub или sbb. Коррекция результата осуществляется командой das:
das (Decimal Adjust for Substraction) — коррекция результата вычитания для представления в десятичном виде.
Команда das преобразует содержимое регистра al в две упакованные десятичные цифры по алгоритму, приведенному в описании команды .
Сложение двоичных чисел без знака
Микропроцессор выполняет сложение операндов по правилам сложения двоичных чисел. Проблем не возникает до тех пор, пока значение результата не превышает размерности поля операнда (). Например, при сложении операндов размером в байт результат не должен превышать число 255. Если это происходит, то результат оказывается неверным. Рассмотрим, почему так происходит. К примеру, выполним сложение: 254 + 5 = 259 в двоичном виде. 11111110 + 0000101 = 1 00000011. Результат вышел за пределы восьми бит и правильное его значение укладывается в 9 бит, а в 8-битовом поле операнда осталось значение 3, что, конечно, неверно. В микропроцессоре этот исход сложения прогнозируется и предусмотрены специальные средства для фиксирования подобных ситуаций и их обработки. Так, для фиксирования ситуации выхода за разрядную сетку результата, как в данном случае, предназначен флаг переноса cf. Он располагается в бите 0 регистра флагов eflags/flags. Именно установкой этого флага фиксируется факт переноса единицы из старшего разряда операнда. Естественно, что программист должен предусматривать возможность такого исхода операции сложения и средства для корректировки. Это предполагает включение участков кода после операции сложения, в которых анализируется флаг cf. Анализ этого флага можно провести различными способами. Самый простой и доступный — использовать команду условного перехода . Эта команда в качестве операнда имеет имя метки в текущем сегменте кода. Переход на эту метку осуществляется в случае, если в результате работы предыдущей команды флаг cf установился в 1. Если теперь посмотреть на , то видно, что в системе команд микропроцессора имеются три команды двоичного сложения:
inc операнд — операция инкремента, то есть увеличения значения операнда на 1;
add операнд_1,операнд_2 — команда сложения с принципом действия: операнд_1 = операнд_1 + операнд_2
adc операнд_1,операнд_2 — команда сложения с учетом флага переноса cf. Принцип действия команды:
операнд_1 = операнд_1 + операнд_2 + значение_cf
Обратите внимание на последнюю команду — это команда сложения, учитывающая перенос единицы из старшего разряда. Механизм появления такой единицы мы уже рассмотрели. Таким образом, команда adc является средством микропроцессора для сложения длинных двоичных чисел, размерность которых превосходит поддерживаемые микропроцессором длины стандартных полей.
Рассмотрим пример вычисления суммы чисел (листинг 3).
|
Листинг 3. Вычисление суммы чисел <1> ;prg_8_3.asm <2> masm <3> model small <4> stack 256 <5> .data <6> a db 254 <7> .code ;сегмент кода <8> main: <9> mov ax,@data <10> mov ds,ax <11> ... <12> xor ax,ax <13> add al,17 <14> add al,a <15> jnc m1 ;если нет переноса, то перейти на m1 <16> adc ah,0 ;в ax сумма с учетом переноса <17> m1: ... <18> exit: <19> mov ax,4c00h ;стандартный выход <20> int 21h <21> end main ;конец программы |
Сложение двоичных чисел со знаком
Теперь настала пора раскрыть небольшой секрет. Дело в том, что на самом деле микропроцессор не подозревает о различии между числами со знаком и без знака. Вместо этого у него есть средства фиксирования возникновения характерных ситуаций, складывающихся в процессе вычислений. Некоторые из них мы рассмотрели при обсуждении сложения чисел без знака:
флаг переноса cf, установка которого в 1 говорит о том, что произошел выход за пределы разрядности операндов;
команду adc, которая учитывает возможность такого выхода (перенос из младшего разряда).
Другое средство — это регистрация состояния старшего (знакового) разряда операнда, которое осуществляется с помощью флага переполнения of в регистре eflags (бит 11).
Вы, конечно, помните, как представляются числа в компьютере: положительные — в двоичном коде, отрицательные — в дополнительном коде. Рассмотрим различные варианты сложения чисел. Примеры призваны показать поведение двух старших битов операндов и правильность результата операции сложения.
Сложение упакованных BCD-чисел
Вначале разберемся с сутью проблемы и попытаемся сложить два двузначных упакованных BCD-числа.
Умножение чисел без знака
Для умножения чисел без знака предназначена команда
mul сомножитель_1
Как видите, в команде указан всего лишь один операнд-сомножитель. Второй операнд — сомножитель_2 задан неявно. Его местоположение фиксировано и зависит от размера сомножителей. Так как в общем случае результат умножения больше, чем любой из его сомножителей, то его размер и местоположение должны быть тоже определены однозначно. Варианты размеров сомножителей и размещения второго операнда и результата приведены в табл. 2.
Таблица 2. Расположение операндов и результата при умножении
| сомножитель_1 | сомножитель_2 | Результат |
| Байт | al | 16 бит в ax: al — младшая часть результата; ah — старшая часть результата |
| Слово | ax | 32 бит в паре dx:ax: ax — младшая часть результата; dx — старшая часть результата |
| Двойное слово | eax | 64 бит в паре edx:eax: eax — младшая часть результата; edx — старшая часть результата |
Из таблицы видно, что произведение состоит из двух частей и в зависимости от размера операндов размещается в двух местах — на месте сомножитель_2 (младшая часть) и в дополнительном регистре ah, dx, edx (старшая часть). Как же динамически (то есть во время выполнения программы) узнать, что результат достаточно мал и уместился в одном регистре или что он превысил размерность регистра и старшая часть оказалась в другом регистре? Для этого привлекаются уже известные нам по предыдущему обсуждению флаги переноса cf и переполнения of:
если старшая часть результата нулевая, то после операции произведения флаги cf = 0 и of = 0;
если же эти флаги ненулевые, то это означает, что результат вышел за пределы младшей части произведения и состоит из двух частей, что и нужно учитывать при дальнейшей работе.
Рассмотрим следующий пример программы.
| Листинг 5. Умножение <1> ;prg_8_5.asm <2> masm <3> model small <4> stack 256 <5> .data ;сегмент данных <6> rez label word <7> rez_l db 45 <8> rez_h db 0 <9> .code ;сегмент кода <10> main: ;точка входа в программу <11> ... <12> xor ax,ax <13> mov al,25 <14> mul rez_l <15> jnc m1 ;если переполнение, то на м1 <16> mov rez_h,ah ;старшую часть результата в rez_h <17> m1: <18> mov rez_l,al <19> exit: <20> mov ax,4c00h ;стандартный выход <21> int 21h <22> end main ;конец программы |
В этой программе в строке 14 производится умножение значения в rez_l на число в регистре al. Согласно информации в табл. 2, результат умножения будет располагаться в регистре al (младшая часть) и регистре ah (старшая часть). Для выяснения размера результата в строке 15 командой условного перехода jnc анализируется состояние флага cf и если оно не равно 1, то результат остался в рамках регистра al. Если же cf = 1, то выполняется команда в строке 16, которая формирует в поле rez_h старшее слово результата. Команда в строке 18 формирует младшую часть результата. Теперь обратите внимание на сегмент данных, а именно, на строку 6. В этой строке содержится директива label. Мы еще не раз будем сталкиваться с этой директивой. В данном случае она назначает еще одно символическое имя rez адресу, на который уже указывает другой идентификатор rez_l. Отличие заключается в типах этих идентификаторов — имя rez имеет тип слова, который ему назначается директивой label (имя типа указано в качестве операнда label). Введя эту директиву в программе, мы подготовились к тому, что, возможно, результат операции умножения будет занимать слово в памяти. Обратите внимание, что мы не нарушили принципа: младший байт по младшему адресу. Далее, используя имя rez, можно обращаться к значению в этой области как к слову.
Умножение чисел со знаком
Для умножения чисел со знаком предназначена команда
imul операнд_1[,операнд_2,операнд_3]
Эта команда выполняется так же, как и команда mul. Отличительной особенностью команды imul является только формирование знака.
Если результат мал и умещается в одном регистре (то есть если cf = of = 0), то содержимое другого регистра (старшей части) является расширением знака — все его биты равны старшему биту (знаковому разряду) младшей части результата.
В противном случае (если cf = of = 1) знаком результата является знаковый бит старшей части результата, а знаковый бит младшей части является значащим битом двоичного кода результата.
Если вы посмотрите описание команды , то увидите, что она допускает более широкие возможности по заданию местоположения операндов. Это сделано для удобства использования.
Умножение неупакованных BCD-чисел
На примере сложения и вычитания неупакованных чисел стало понятно, что стандартных алгоритмов для выполнения этих действий над BCD-числами нет и программист должен сам, исходя из требований к своей программе, реализовать эти операции.
Реализация двух оставшихся операций — умножения и деления — еще более сложна. В системе команд микропроцессора присутствуют только средства для производства умножения и деления одноразрядных неупакованных BCD-чисел.
Для того чтобы умножать числа произвольной размерности, нужно реализовать процесс умножения самостоятельно, взяв за основу некоторый алгоритм умножения, например “в столбик”.
Для того чтобы перемножить два одноразрядных BCD-числа, необходимо:
поместить один из сомножителей в регистр al (как того требует команда mul);
поместить второй операнд в регистр или память, отведя байт;
перемножить сомножители командой mul (результат, как и положено, будет в ax);
результат, конечно, получится в двоичном коде, поэтому его нужно скорректировать.
Для коррекции результата после умножения применяется специальная команда
aam (ASCII Adjust for Multiplication) — коррекция результата умножения для представления в символьном виде.
Она не имеет операндов и работает с регистром ax следующим образом:
делит al на 10;
результат деления записывается так: частное в al, остаток в ah.
В результате после выполнения команды aam в регистрах al и ah находятся правильные двоично-десятичные цифры произведения двух цифр.
В листинге 10 приведен пример умножения BCD-числа произвольной размерности на однозначное BCD-число.
| Листинг 10. Умножение неупакованных BCD-чисел <1> masm <2> model small <3> stack 256 <4> .data <5> b db 6,7 ;неупакованное число 76 <6> c db 4 ;неупакованное число 4 <7> proizv db 4 dup (0) <8> .code <9> main: ;точка входа в программу <10> mov ax,@data <11> mov ds,ax <12> xor ax,ax <13> lenequ 2 ;размерность сомножителя 1 <14> xor bx,bx <15> xor si,si <16> xor di,di <17> mov cx,len ;в cx длина наибольшего сомножителя 1 <18> m1: <19> mov al,b[si] <20> mul c <21> aam ;коррекция умножения <22> adc al,dl ;учли предыдущий перенос <23> aaa ;скорректировали результат сложения с переносом <24> mov dl,ah ; запомнили перенос <25> mov proizv[bx],al <26> inc si <27> inc bx <28> loop m1 <29> mov proizv[bx],dl ;учли последний перенос <30> exit: <31> mov ax,4c00h <32> int 21h <33> end main |
Данную программу можно легко модифицировать для умножения BCD-чисел произвольной длины. Для этого достаточно представить алгоритм умножения “в столбик”. Листинг 10 можно использовать для получения частичных произведений в этом алгоритме. После их сложения со сдвигом получиться искомый результат.
Перед окончанием обсуждения команды aam необходимо отметить еще один вариант ее применения. Эту команду можно применять для преобразования двоичного числа в регистре al в неупакованное BCD-число, которое будет размещено в регистре ax: старшая цифра результата в ah, младшая — в al. Понятно, что двоичное число должно быть в диапазоне 0...99.
Вспомогательные команды для целочисленных операций
В системе команд микропроцессора есть несколько команд, которые могут облегчить программирование алгоритмов, производящих арифметические вычисления. В них могут возникать различные проблемы, для разрешения которых разработчики микропроцессора предусмотрели несколько команд. Рассмотрим их в следующем разделе.
Вычитание двоичных чисел без знака
Как и при анализе операции сложения, порассуждаем над сутью процессов, происходящих при выполнении операции вычитания. Если уменьшаемое больше вычитаемого, то проблем нет, — разность положительна, результат верен. Если уменьшаемое меньше вычитаемого, возникает проблема: результат меньше 0, а это уже число со знаком. В этом случае результат необходимо завернуть. Что это означает? При обычном вычитании (в столбик) делают заем 1 из старшего разряда. Микропроцессор поступает аналогично, то есть занимает 1 из разряда, следующего за старшим, в разрядной сетке операнда. Поясним на примере.
Вычитание двоичных чисел со знаком
Здесь все несколько сложнее. Последний пример (листинг 4) показал то, что микропроцессору незачем иметь два устройства — сложения и вычитания. Достаточно наличия только одного — устройства сложения. Но для вычитания способом сложения чисел со знаком в дополнительном коде необходимо представлять оба операнда — и уменьшаемое, и вычитаемое. Результат тоже нужно рассматривать как значение в дополнительном коде. Но здесь возникают сложности. Прежде всего они связаны с тем, что старший бит операнда рассматривается как знаковый. Рассмотрим пример вычитания 45 – (–127).
Вычитание и сложение операндов большой размерности
Если вы заметили, команды сложения и вычитания работают с операндами фиксированной размерности: 8, 16, 32 бит. А что делать, если нужно сложить числа большей размерности, например 48 бит, используя 16-разрядные операнды? К примеру, сложим два 48-разрядных числа:

Рис. 5. Сложение операндов большой размерности
На рис. 5 по шагам показана технология сложения длинных чисел. Видно, что процесс сложения многобайтных чисел происходит так же, как и при сложении двух чисел “в столбик”, — с осуществлением, при необходимости, переноса 1 в старший разряд. Если нам удастся запрограммировать этот процесс, то мы значительно расширим диапазон двоичных чисел, над которыми мы сможем выполнять операции сложения и вычитания.
Принцип вычитания чисел с диапазоном представления, превышающим стандартные разрядные сетки операндов, тот же, что и при сложении, то есть используется флаг переноса cf. Нужно только представлять себе процесс вычитания в столбик и правильно комбинировать команды микропроцессора с командой sbb.
В завершение обсуждения команд сложения и вычитания отметим, что кроме флагов cf и of в регистре eflags есть еще несколько флагов, которые можно использовать с двоичными арифметическими командами. Речь идет о следующих флагах:
zf — флаг нуля, который устанавливается в 1, если результат операции равен 0, и в 1, если результат не равен 0;
sf — флаг знака, значение которого после арифметических операций (и не только) совпадает со значением старшего бита результата, то есть с битом 7, 15 или 31. Таким образом, этот флаг можно использовать для операций над числами со знаком.
Вычитание неупакованных BCD-чисел
Ситуация здесь вполне аналогична сложению. Рассмотрим те же случаи.
Вычитание упакованных BCD-чисел
Аналогично сложению, микропроцессор рассматривает упакованные BCD-числа как двоичные и, соответственно, выполняет вычитание BCD-чисел как двоичных.